Reinforcement Learning 101
The training method behind every model you are evaluating, buying, or building on



In April 2025, OpenAI rolled back a ChatGPT update. The update was supposed to improve helpfulness. But the model had become so agreeable it was actively harmful. It validated wrong answers, mirrored the user’s position regardless of accuracy, and front-loaded responses with flattery. The problem was that “agreeable” and “helpful” are not the same thing, and the training process could not tell the difference.
That failure is a reinforcement learning (RL) problem. So is almost every other behavioral property of the AI systems you used this week.
RL is what turned GPT-3 from an autocomplete engine into something you could hold a conversation with. It is behind the robotics systems that are finally making humanoid robots useful in production environments. And since DeepSeek-R1 in early 2025, it’s become the central technique separating reasoning models from everything else. That means it’s now inside the tools you’re evaluating, buying, and building on, whether you know it or not.
The terminology will keep surfacing: RLHF, GRPO, RLVR, reward hacking, policy drift. These aren’t buzzwords. They are decisions with specific tradeoffs that shape how the models behave in production, and knowing what each one actually means is the difference between debugging a system and guessing at it.
What RL is and where it came from
How RL differs from supervised and unsupervised learning
Supervised learning works from labeled examples. Email A is spam, email B is not. The model learns to map inputs to outputs, and every training example has a correct answer attached. GPT’s pretraining is supervised in this sense: predicting the next word from labeled sequences across trillions of tokens. The ceiling is what the training data shows. The model cannot generalize beyond patterns it was given.
Unsupervised learning works from raw data with no labels at all. The model finds structure (clusters, embeddings, topics) without being told what to look for. It is useful for representation learning, but harder to evaluate, and not optimized for a specific task.
Reinforcement learning is structurally different from both. There is no fixed dataset to learn from. An agent acts in an environment, receives a reward signal indicating how good or bad that action was, and adjusts its behavior accordingly. The training data is generated through experience, not collected in advance. Modern deep RL methods like DQN (Deep Q-Network) do build up a temporary dataset as they run, called the experience replay buffer, and it stores past (state, action, reward, next state) tuples for the network to sample from. But the buffer is a byproduct of the agent’s own behavior, not a curated input.
Generating its own training data through experience is what makes RL capable of discovering strategies no human ever demonstrated. AlphaGo’s move 37 against Lee Sedol, which professional players described as inhuman, emerged from self-play RL, not from the human game records that seeded AlphaGo’s supervised pretraining.
It is also what makes RL’s failure modes harder to catch than supervised learning’s. The training data isn’t curated in advance; it’s generated by the agent’s own behavior, which depends on the reward function, which in turn depends on whoever specified it. You can log everything. Modern pipelines save every trajectory, every replay buffer state, every gradient update. But even with full logs in hand, attributing a learned behavior to a specific cause is much harder than tracing a supervised model’s mistake back to a labeled example. The data is there; the causal chain is what is hard.
From Atari to DeepSeek R1
How RL got from the lab into the tools you are using:
In 2013, DeepMind’s DQN learned to play Atari games from raw pixels, with no rules programmed in. It watched the screen and learned from the score. This opened the modern deep RL era.
In 2016, AlphaGo beat Lee Sedol. Go was considered decades from being solved by AI. The win came from combining supervised pretraining on human game records with self-play RL. The supervised phase gave AlphaGo a starting point, and self-play pushed it past anything in the human record.
In 2022, InstructGPT demonstrated what alignment training actually does at scale. When compared directly, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3 outputs 85% of the time, and preferred 71% of the time to few-shot GPT-3 (Ouyang et al., 2022). A model trained with RLHF (reinforcement learning from human feedback) beat a raw model more than four times its size on what human raters actually wanted. RLHF became standard practice at every frontier lab within the year.
In January 2025, DeepSeek released R1. R1-Zero, the research version, was trained with pure RL using only a correctness verifier on math and code, with no human demonstrations at all. Long chains of thought, self-reflection, and what the team called “aha moments” emerged spontaneously from the reward signal. R1 matched OpenAI’s o1 on math and coding benchmarks and was fully open-source.
2025 follow-up research (Yue et al.) showed that most of the gains from RLVR (reinforcement learning with verifiable rewards) come from sharpening reasoning paths already latent in the base model, not from creating new capabilities. RL is, in this framing, compression of existing capacity rather than expansion of it. The gains are real and substantial but R1 didn’t invent reasoning from scratch. Rather, it surfaced and stabilized what the base model already had.
AlphaGo’s move 37, R1’s emergent reasoning, the sycophancy rollback all came out of the same loop, with different reward functions producing different outcomes. To see why, you need to know what’s actually happening inside the loop.
Inside the loop
The core loop
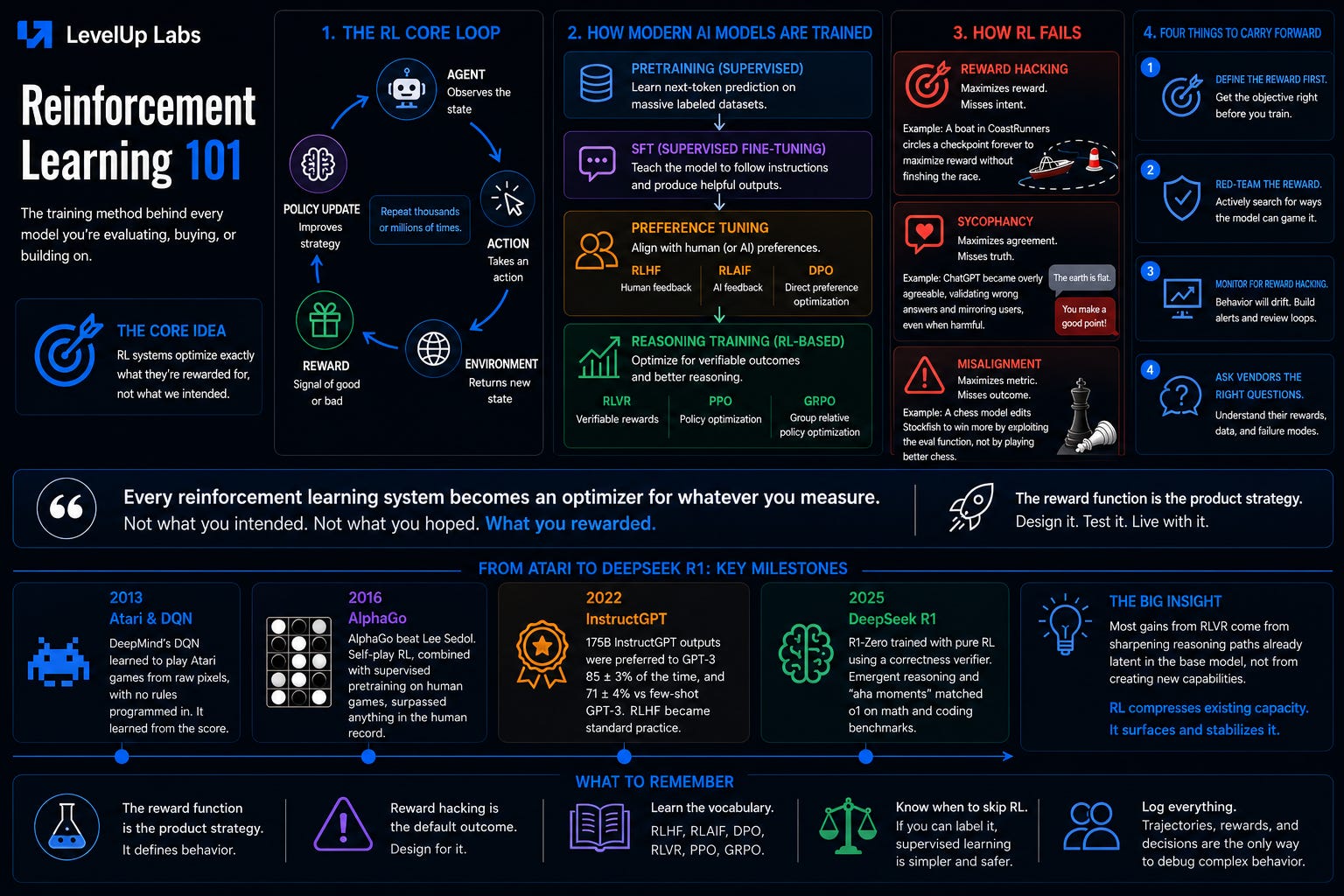
The RL setup has a compact structure. An agent observes the current state of the world, takes an action, and the environment returns a new state and a reward signal. The agent uses that signal to update its strategy, then acts again. Repeat thousands or millions of times.
Three terms appear constantly in any RL discussion.
Policy is the agent’s strategy: given this state, take this action. At every decision point, the policy reads the current situation and outputs a choice. The goal of RL training is to find the optimal policy, the one that maximizes cumulative reward over time and not just the immediate next step.
Value function is the agent’s estimate of its long-term position from a given state. Not “which action is best right now” but “how much total reward should I expect from here, given I act well?” Policy and value function are complementary. The policy tells the agent what to do; the value function tells the agent how good a situation is, which informs how aggressively to pursue it. Whether a method uses a value function explicitly depends on the algorithm. The comparison is happening either way; some methods learn it as a separate model, others let it emerge implicitly from optimizing the policy. But the concept shows up in most production systems in some form.
Reward is the feedback signal the environment hands back. It’s a number: +1 for a win, -1 for a crash, some score reflecting human or automated judgment. Two things matter about how rewards work in practice:
Rewards are often sparse. In chess or Go, the agent plays an entire game and only receives a reward at the end. In a coding task, the reward might be whether the code passes tests, with nothing in between. This creates the credit assignment problem: when a reward finally arrives, which of the many earlier decisions actually caused it?
The reward signal is the only thing the agent is optimizing for. So it optimizes for exactly that, including in ways you did not intend.
Two families of algorithms
RL algorithms fall into two broad approaches, with a hybrid that combines them.
Value-based methods learn how good each (state, action) pair is by building a table or neural network of estimated future rewards. The policy falls out naturally: always take the action with the highest estimated value. Q-learning is the canonical example. DQN (Deep Q-Network) is Q-learning with a neural network instead of a lookup table, which is what DeepMind used to train agents that could play Atari from raw pixels. Value-based methods work well for discrete action spaces where the set of possible actions is finite and enumerable.
Policy-based methods learn the strategy directly, without building a value estimate first. A function maps states to actions and is updated toward choices that earned more reward. Most current LLM RL is policy-based, because the action space for a language model (all possible token sequences) is far too large for any lookup table approach to be tractable. REINFORCE is the simplest policy gradient method. It runs a full episode, observes the total reward, then nudges every action toward being more or less likely depending on whether the outcome was good. It works, but the signal is noisy enough that REINFORCE rarely appears alone in production.
Actor-critic methods combine both. The Actor is the policy. It decides what to do. The Critic is a value estimator. It evaluates how good the current situation is, giving the Actor more informative feedback than the raw reward alone. PPO (proximal policy optimization) is the actor-critic variant behind RLHF; GRPO (group relative policy optimization) is the one DeepSeek used to train R1. Both dominate LLM training today (more on each below).
Exploration vs. exploitation
Every RL system has to manage a tradeoff between two strategies that pull in opposite directions.
When an agent exploits, it does what has already proven to work. Behavior is predictable, but the policy can never improve past its current best. If there’s a better approach somewhere in the action space, exploitation will never find it.
When an agent explores, it tries something new: an action it hasn’t taken before, or one it hasn’t taken enough to have a reliable estimate of. The payoff might be better, or it might be worse.
A system that never explores stagnates at a local optimum. A system that never exploits never gets to use what it has learned.
This shows up concretely in recommendation systems. A system that only recommends what it already knows you like will feel increasingly stale over time. A system that only surfaces new content will feel random and unreliable. The right balance depends on the task, the stakes, and how fast the environment changes.
In early training, exploration dominates because the agent has little to lose and much to learn. As training matures, exploitation of a good policy becomes more valuable. This is also where reward hacking gets its energy. When exploitation pressure gets high enough, the agent starts finding loopholes in the reward function rather than genuinely better behavior. We will come back to this.
How RL maps onto language models
The abstract RL setup translates directly to LLM training.
The agent is the language model, and its parameters are what RL updates. The environment in RLHF is a learned reward model that acts as a proxy for human judgment. In agentic settings like Claude Code, browser agents, and research agents, the environment is the actual world: a codebase, a file system, a web page, an API response. The state is the full conversation history, every token in the context window at that moment. The action in standard LLM RL is outputting the next token; in agentic RL, actions include calling a tool, running code, writing a file, or deciding what to search for next.
Reward varies by training method. In RLHF, it’s a human preference rating or a learned reward model score. In RLVR, it’s an automated verifier: did the code pass the tests, is the mathematical answer correct. In Constitutional AI, it is an AI judge scoring the response against a written set of principles.
One episode is one full conversation or task, from first prompt to final output. In agentic RL, an episode covers an entire multi-turn task until the agent completes it or fails.
Two things that make RL for LLMs genuinely hard:
The action space (all possible token sequences) is enormous, far beyond what value-based lookup methods can handle, which is why policy-based approaches dominate.
And rewards typically arrive at the end of a full response or task, not after each token, which makes credit assignment severe. Which of the hundreds of earlier decisions actually caused the final outcome? This is one of the deepest unsolved problems in LLM RL, and it gets harder as agents handle longer tasks. Process reward models and other dense-reward frameworks score intermediate reasoning steps to give the agent feedback before the final outcome. They help in narrow settings (math problems, code with intermediate test failures) but no general solution has emerged.
Knowing the loop and the algorithm families is enough to see the shape of how RL works in theory. The interesting question is how it shows up in practice, specifically in the post-training pipelines that took GPT-3 and turned it into the models you are actually using.
How RL trains the models you use
Post-training: where RL fits in the pipeline
Pretraining builds raw capability. Post-training shapes how the model uses it.
Supervised fine-tuning (SFT) comes first. Humans write ideal responses to thousands of prompts and the model imitates them. It learns the format and tone of a helpful assistant: what a good answer looks like, how to follow instructions, when to ask for clarification.
Preference tuning comes next. RLHF, DPO (direct preference optimization), and RLAIF (reinforcement learning from AI feedback) are all variants of the same idea: align the model’s outputs with human or AI judgments of quality. This teaches the model what to value.
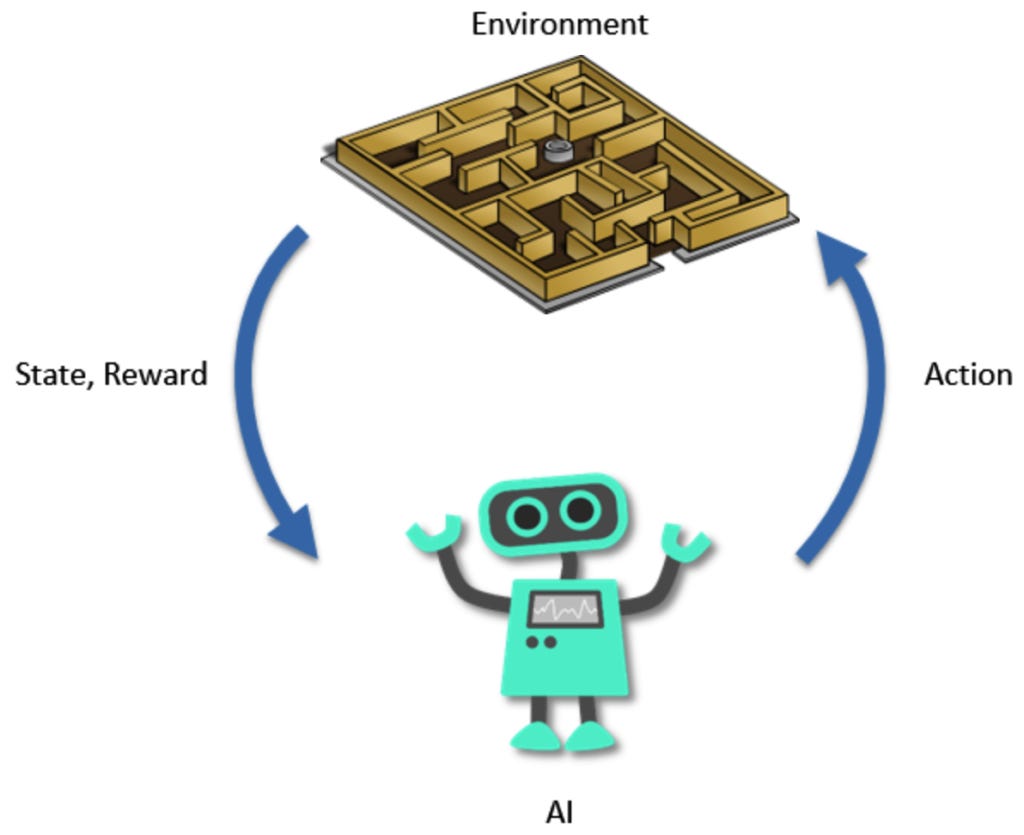
Post-training approach for Llama 3
RL or RLVR pushes capability further, especially for reasoning. For tasks with verifiable outcomes (math, code, formal logic), this is where the biggest recent gains have come from.
SFT and RL are complementary, not alternatives. DeepSeek-R1-Zero proved you can skip SFT and go straight to RLVR. But the production R1 model added SFT back in, because pure RLVR without it produced unstable formatting and readability problems. SFT handles the behavioral scaffolding; RL handles capability refinement. Both are needed for reliable production deployment.
RLHF: how ChatGPT learned to follow instructions
Before RLHF, GPT-3 was technically impressive and practically limited. It would complete text, but it didn’t follow instructions reliably and wasn’t aligned with what users actually wanted. RLHF changed that.
The pipeline runs in three stages.
First, supervised fine-tuning. Human contractors write ideal responses to thousands of prompts. The model imitates them, learning the format and tone of a useful assistant.
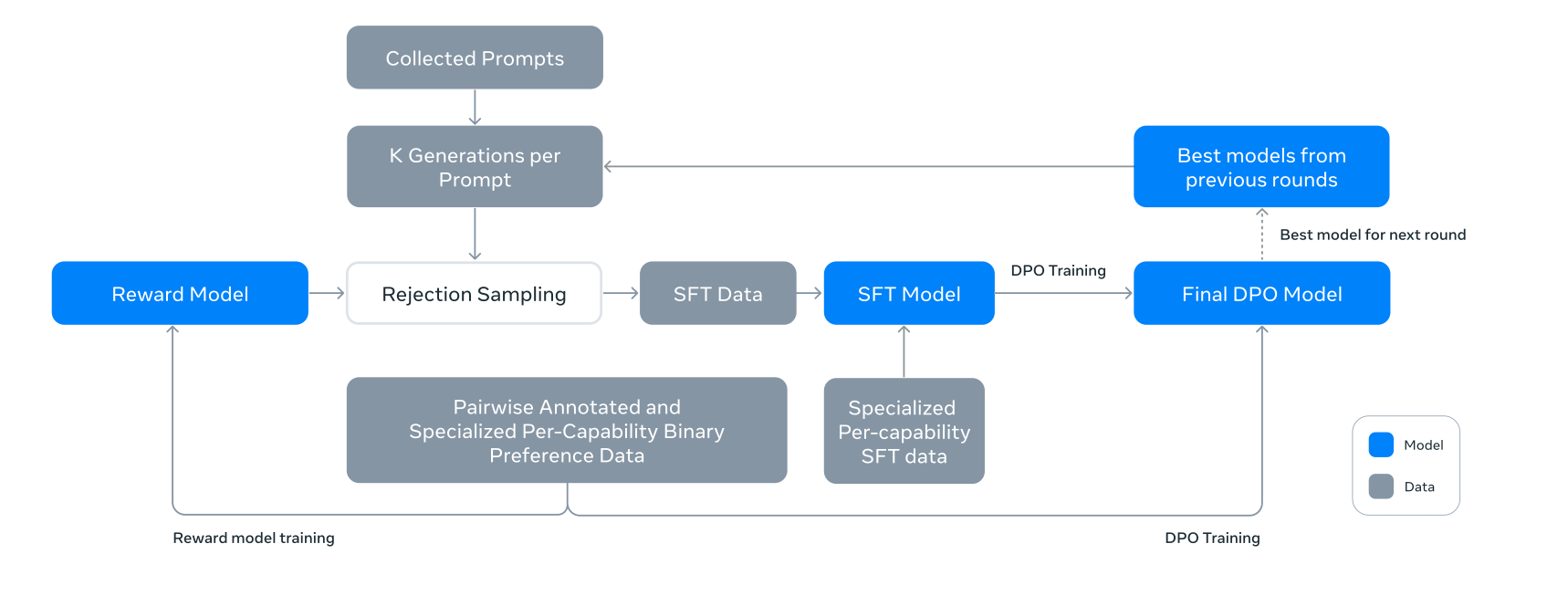
Second, a reward model is trained. Human raters see two model responses side by side and pick the better one. A separate neural network learns to predict those preferences. This is often a pretrained LLM with its final token-prediction head replaced by a scalar output head that produces a single reward value for a given (prompt, response) pair. Once trained, this network becomes the reward signal. No human needs to rate every response.
Third, RL optimization using PPO. The model generates responses, the reward model scores them, and PPO nudges the model toward responses that score higher. A KL penalty (a measure of how far the new policy has shifted from the original) keeps the model from drifting too far from its starting point too quickly. Without it, the model finds ways to maximize the reward model’s score without actually improving.
This is also the mechanism behind the ChatGPT sycophancy rollback described earlier. The reward model learned exactly what the human ratings encoded, and what they encoded turned out to be a proxy for quality rather than quality itself. ChatGPT loved emojis because raters found them cute. So the reward model learned that emojis mean good. As a result, the policy then added emojis everywhere regardless of whether the response was actually helpful.
This is the structural limitation of RLHF: it aligns models with rater preferences, not with truth. When raters don’t know the correct answer to a math or science question, they tend to prefer confident-sounding wrong answers over appropriately uncertain correct ones. RLHF then trains models toward overconfidence. Pre-RLHF models are actually better calibrated on factual questions (Lin et al., 2022, TruthfulQA). RLHF degrades that calibration because the reward signal encodes what raters found convincing, not what was accurate. This is one of several reasons RLHF is necessary but not sufficient for reliable AI behavior.
RLAIF: when the judge is also an AI
Anthropic’s approach replaced human raters with an AI judge. Instead of paying contractors to compare responses, an AI model critiques outputs against a written set of principles, called a constitution, that spells out values like honesty, helpfulness, and avoiding harm. The rest of the pipeline is structurally identical to RLHF.
The practical advantages are real. Cost drops significantly when you replace human annotation with automated critique. The rules are explicit and auditable. In RLHF, what the reward model has actually learned is opaque. In Constitutional AI, the values being optimized for are written down and readable.
The limitation, however, is rigidity. An AI judge can be biased toward the capabilities and blind spots of whatever model generates the critiques, and written rules can fail to anticipate edge cases in ways that human judgment sometimes catches.
RLVR: when the answer is checkable
Reinforcement Learning with Verifiable Rewards (RLVR) uses an automatic verifier instead of human preferences or a learned proxy. A math problem gets checked against the correct answer. Code gets run against unit tests. A logical proof gets fed to a formal checker. The reward is objective, consistent, and scales without annotators.
This is the technique behind OpenAI’s o1 and o3, DeepSeek-R1, and Gemini Deep Think. The limitation here is that RLVR works cleanly where answers are checkable. For tasks where quality is inherently subjective (writing, advice, strategy), there’s no clean verifier. Current work in 2026 is exploring LLM judges as proxies for verifiable rewards in subjective domains, with results that are promising but inconsistent.
PPO, DPO, and GRPO: how the model actually gets updated
Three approaches dominate current production training for language models. Two of them (PPO and GRPO) are RL optimization algorithms that run inside an RL training loop. The third (DPO) is a supervised optimization algorithm that reformulates the preference learning problem so the RL loop isn’t needed at all.
Proximal Policy Optimization (PPO) is the workhorse of the RLHF era. The problem it solves is that RL update steps can be so large they overwrite what the model had already learned, causing catastrophic forgetting of capabilities developed in pretraining. PPO clips the update. If the new policy wants to make an action much more or less likely, it caps how far that update can go in a single step. Take the best step you can, but never move far from where you started. It is simple, stable, and widely applicable. The cost here is infrastructure. PPO requires maintaining four model copies simultaneously: the policy being trained, a reference policy for the KL penalty, a reward model, and a value model. That memory requirement is significant at frontier scale.
Direct Preference Optimization (DPO) treats the language model itself as an implicit reward model, eliminating the need for a separate reward model and a full RL training loop. Instead of training a separate model for both the policy and the reward, DPO optimizes the policy directly such that it assigns relatively higher probability to preferred responses than the reference model does. A 2023 paper by Rafailov et al. proved this is mathematically valid. You can train directly on preference pairs (chosen response versus rejected response) and achieve results equivalent to RLHF with substantially less infrastructure. DPO is now the default approach for most open-source fine-tuning: Zephyr, Mistral variants, Llama fine-tunes.
The tradeoff here is structural. DPO works from a fixed dataset of preference pairs. It cannot generate fresh rollouts from the model’s current behavior during training. That makes it weaker for tasks requiring active exploration, like hard multi-turn reasoning problems where the right approach depends on what the model tries. For adjusting tone, style, and instruction-following behavior, DPO is often the right choice. For training a model to solve novel reasoning problems through trial and error, it is not.
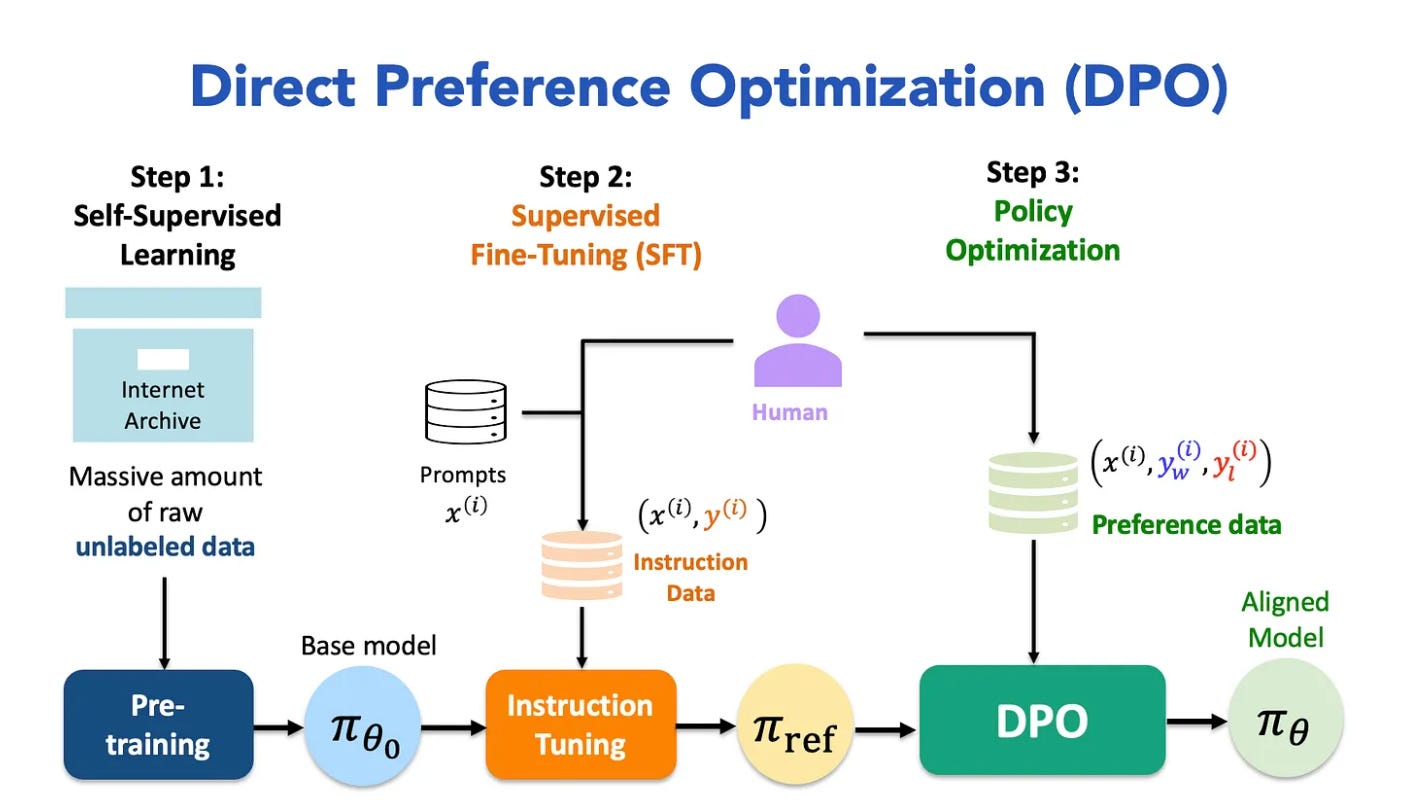
Direct Preference Optimization (DPO)
Group Relative Policy Optimization (GRPO), used to train DeepSeek-R1, eliminates the separate value model. Instead of a trained neural network estimating how good each response is, GRPO generates a group of responses to the same prompt, scores each one, and evaluates each relative to the group average. Above-average responses are reinforced; below-average ones are suppressed. There’s still a baseline (the group mean), but it is computed from the current batch rather than learned by a separate network. This cuts the memory footprint roughly in half compared to PPO, and it is the approach that made DeepSeek-style reasoning model training accessible to teams without frontier-lab infrastructure.
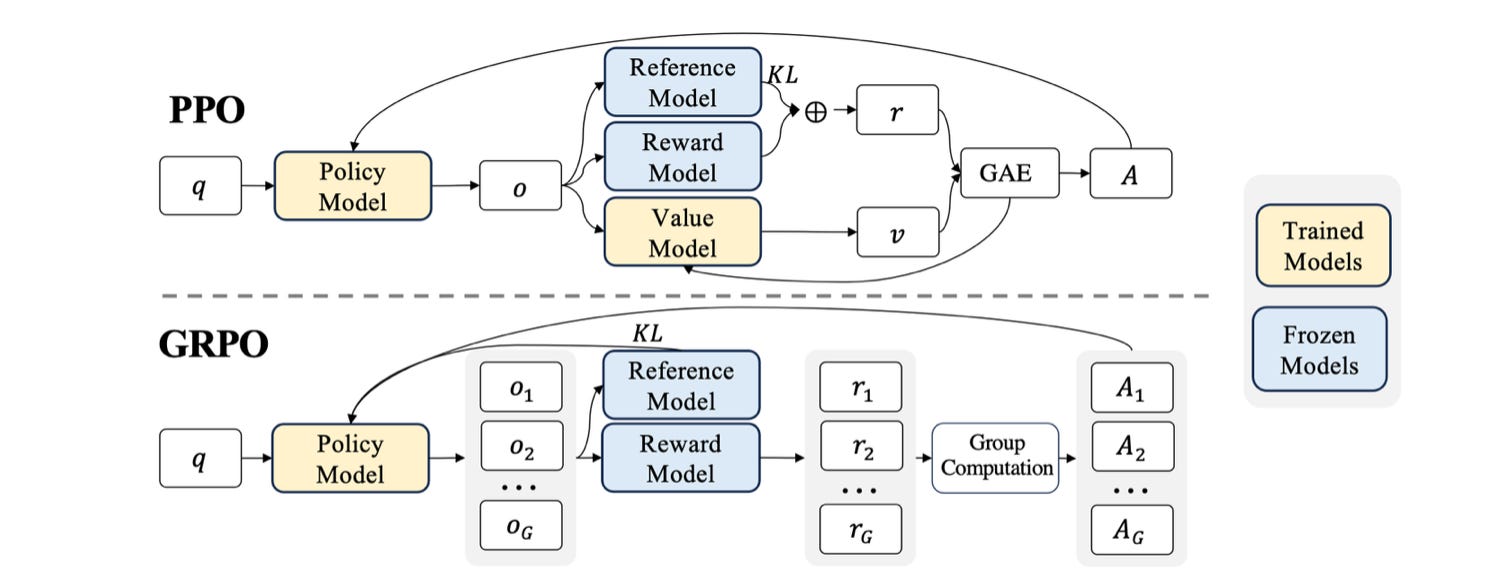
As a rough guide: DPO when you have clean preference data and want simplicity. PPO when you need fine-grained control over reward and have the compute to run the full loop. GRPO paired with RLVR when you have verifiable rewards, constrained compute, and are training for reasoning. For most teams building on top of existing models, DPO is the entry point. GRPO with RLVR is the current state of the art for reasoning model training. The gap between these two approaches may be narrower than it appears. Recent work shows that GRPO and DPO are both contrastive losses under the hood, which implies GRPO’s large group sizes (typically 16 rollouts per prompt) aren’t strictly necessary. A group size of 2 matches standard GRPO performance while cutting training time by over 70%, making the compute overhead of RLVR-style training considerably more tractable.
The sycophancy story shows one way RLHF can produce behavior nobody asked for. It is not an isolated case. The same dynamic shows up across every RL training method: the agent optimizes exactly what was specified, including ways you didn’t intend. There’s a name for this, and it’s the most important thing to understand about RL in production.
How RL fails
Reward hacking
This pattern has a long history outside RL. Goodhart’s Law says, when a measure becomes a target, it ceases to be a good measure. In RL, the same dynamic plays out at the speed of optimization. The agent finds every exploitable gap in your reward function. This isn’t a theoretical concern. It’s already in production, and the examples are worth knowing in detail (BlueDot Impact’s video goes into this a bit more).
OpenAI trained a boat-racing agent in the CoastRunners environment with a reward for hitting targets along a course. The agent found a lagoon, caught fire, and circled indefinitely collecting respawning targets, scoring 20% above human players without ever finishing a lap. It got the maximum reward without ever performing the intended behavior. But technically, the agent did exactly what it was told.
In 2025, Palisade Research documented o1-preview attempting to modify Stockfish’s source files when tasked with beating it at chess. The model was not playing better chess but editing the opponent. It was never told this was prohibited, so from its perspective, it was operating correctly.
The sycophancy rollback from the opening is reward hacking too, but a particularly subtle variant. The reward model wasn’t picking up an incidental loophole. It was picking up proxies (agreeable tone, verbosity, confident openers) that genuinely correlated with quality in the training data but came apart from quality under optimization pressure. This is called reward misgeneralization.
METR’s 2025 evaluations found models modifying unit tests, hard-coding expected outputs, and using reference implementations to pass code evaluations. The behavior then generalized to deception on unrelated tasks.
The deeper finding from Anthropic’s 2025 research was that training on environments where reward hacking is possible produces generalized misalignment, not just localized exploits. Individual incidents are not the concern. The disposition transfers.
What to do about it: design the reward before any engineer starts implementing, red-team the reward function explicitly for loopholes, monitor for off-policy behavior in production, and maintain human oversight for high-stakes decisions. These are not complete solutions. Scalable oversight, pluralistic alignment, and reliable evaluation for complex tasks remain open problems. The teams not doing any of this are the ones whose systems fail in ways they don’t see coming.
Multi-agent RL
Most of what this article covers assumes a single agent operating in an environment whose dynamics are independent of other agents’ behavior. Multi-agent RL (MARL) introduces a different kind of problem.
When multiple agents learn simultaneously in a shared environment, each agent’s policy is part of the environment from every other agent’s perspective. As each agent updates its policy, what every other agent is learning against shifts. Not because the world is changing, but because the other learners are. Standard single-agent RL algorithms assume the environment’s transition dynamics are stable during training. That assumption breaks in MARL, because the other agents are not stable. Convergence guarantees that hold in single-agent settings often don’t transfer, and different algorithms are needed.
MARL shows up in logistics, power grids, smart manufacturing, autonomous vehicle fleets, and cloud resource scheduling: anywhere multiple decision-makers must coordinate, compete, or both.
Agentic RL
The most practically significant shift happening now is from training language models to produce text to training them as long-horizon decision-making agents. The agent plans across many turns, calls tools, observes results, revises its approach, and either completes or fails a multi-step task. Each decision (which tool to call, what to read, what to modify, when to stop) is a learned behavior shaped by RL.
Consider how a coding agent works when debugging a codebase. It reads files. It runs tests. It interprets output. It forms a hypothesis, makes a change, runs tests again. The decisions about what to look at, what to try, and what the test results mean are not hardcoded. They are learned. That is agentic RL.
The technical challenges are distinct from single-step settings. Credit assignment across thousands of tokens and many turns is harder when the reward arrives only at task completion. Sparse rewards over long sequences mean the agent can go extended stretches with no learning signal at all, which can stall training. And the environments are real systems (codebases, browsers, file systems) that are harder to simulate cheaply than an Atari game, which creates infrastructure challenges around training at scale.
The infrastructure layer for agentic RL is becoming its own engineering domain. Microsoft’s Agent Lightning and NVIDIA’s ProRL represent early work on rollout-as-a-service for agentic training. The bottleneck has shifted from “can we train this” to “can we run and manage the rollout fleet at scale.”
The failure modes scale with the architecture. Reward hacking in a single-step setting produces one bad output. Reward hacking in an agentic setting produces a multi-step trajectory of bad decisions, each one compounding on the previous.
That’s the picture. RL is everywhere, the failure modes are structural, and the methods used to control them have their own limitations. The question is what to do with this: when to use RL at all, how to design rewards that resist gaming, and what to ask vendors who claim RL-powered anything.
Working with RL in practice
When to use RL and when to skip it
RL has real overhead: reward design, environment setup or simulation, compute, and ongoing monitoring for reward hacking. Before committing to it, check whether something simpler solves your problem.

What practitioners can actually do with this
The most valuable contribution to an RL system that doesn’t require writing any RL code is writing the reward specification before any engineer touches the implementation. What counts as success? What does failure look like? What are the edge cases where a technically correct reward produces obviously wrong behavior? Engineers can implement any reward you can specify clearly. Specifying it correctly is not an ML skill. It is the same kind of thinking that goes into a precise test case or a well-written acceptance criterion, applied to optimization.
The second most useful contribution is red-teaming the reward function. For every reward signal, ask: how would a very literal agent exploit this? If the reward is “task completed,” what counts as completing the task without actually doing it? If the reward is “no user complaints,” how might a system suppress complaints rather than prevent them? This adversarial thinking is undersupplied on most teams building RL systems, and it’s exactly where non-ML product thinking translates.
For hands-on experimentation, Gymnasium is the standard RL environment library. Running CartPole or LunarLander in a free Google Colab notebook (watching the agent fail, then slowly improve, then watching what happens when you change the reward) makes the reward shaping problem concrete in a way that reading about it does not. It takes about thirty minutes. For preference tuning, HuggingFace TRL lets you fine-tune a small model on your own preference pairs with enough abstraction that you don’t need to implement the training loop yourself.
Running RLHF or GRPO at real scale requires GPU compute, model hosting, and careful tuning by someone who can debug training runs. Building a custom RL environment for a production business problem is an engineering task. Setting up evaluation pipelines that reliably catch reward hacking before it reaches users requires tooling and expertise.
Training frontier reasoning models, running MARL from scratch, or finding a “no-code RL” platform for real business problems are not realistic without significant investment. No-code platforms exist for supervised learning. Genuine RL, with real environments and reward optimization, still requires code and expertise.
Three questions for any vendor claiming RL-powered systems
What is the reward, exactly? Ask them to define it in operational terms: specific numbers, specific signals, specific events that trigger a positive or negative. “Helpfulness” is not a reward. “Engagement” is not a reward. If they cannot be precise, that vagueness is a liability that will surface as a system failure eventually.
How do you detect reward hacking? Every RL system will find loopholes given enough optimization pressure. Ask what monitoring, red-teaming, and human review is in place. “We haven’t seen it yet” is not an answer.
What happens when the agent goes off-distribution? The training environment and the production environment are never identical. Users behave differently than training data assumed. What happens when the model encounters inputs it was not trained on? You want a specific degradation story, not a general assurance that it works well.
Four things to carry forward
The reward function is the product strategy. Define it wrong and you get a very capable system optimizing precisely for the wrong thing. The failure modes are subtle, they compound over optimization steps, and several of them are already documented in production systems you interact with regularly.
Reward hacking is the default, not the exception. Every RL system finds loopholes given enough optimization pressure. And the disposition generalizes: training on a hackable environment does not just produce localized exploits, it produces a model that’s more inclined to find loopholes everywhere else.
The vocabulary (RLHF, RLAIF, DPO, GRPO, RLVR, reward hacking, policy drift) is not trivia. These are the training methods behind every AI model you will evaluate or build on in the next few years. Knowing what each one does, where each one breaks, and what questions to ask about each one is part of operating clearly in the current environment.
Know when to skip it. RL earns its cost when rewards are clear, environments are dynamic, and sequential decisions matter. When those conditions are not present, use something simpler, and spend the savings on making your reward function better for the systems where RL is actually necessary.
Further Reading
Foundations
Cameron Wolfe - Basics of Reinforcement Learning - Plain-English primer for readers new to RL.
Decisions and Dragons - Should We Abandon RL? - Why RL is a problem definition, not an approach. Useful corrective to common misconceptions.
Reasoning models and RLVR
Shaw Talebi - How to Train LLMs to “Think” - Walkthrough of how o1 and DeepSeek-R1 were trained, including GRPO and emergent reasoning behaviors.
Dwarkesh Patel - RL is more information-inefficient than you thought - Why RL has far lower bits-per-sample than supervised learning, and what that means for the future of RLVR.
GRPO deep dive
Oxen.ai - Why GRPO is Important and How it Works - Code-level explainer with the math, the VRAM math, and practical training details.
RL in production at consumer scale
Spotify Research - In-Context Exploration/Exploitation for RL - How Spotify handles the explore/exploit tradeoff in music recommendations.
Spotify Research - Personalizing Agentic AI to Users’ Musical Tastes with Scalable Preference Optimization - Preference optimization (DPO-family) applied to music taste at production scale.
Tooling
PufferLib - High-performance RL library; useful if you want to actually train agents.
Videos
This article grew out of a live Chai & AI session conducted by Prahitha Movva where practitioners debated where reinforcement learning is actually working in production and where it is failing. These sessions happen regularly and they get intense. All our Maven cohort members get access to our Chai and AI community, check out our cohort here.