How to Choose Your AI Agent Stack in 2026
A builder’s framework for the feature-parity race




The first part of this series laid out the 2026 AI agent stack as nine layers, covering what exists at each one, which players to watch, and how the picture has shifted since 2025. Mapping the territory, though, is a different thing from charting a route across it.
The question every builder had after Part 1 is the same one they had going in. Which of these players do I actually pick?
It’s a harder question than it sounds, because every meaningful tool in the stack is racing toward feature parity with every other tool in its layer. Vector databases have already converged, runtimes are converging now, and coding harnesses are next in line.
So “which tool is best?” turns out to be the wrong question, since it assumes a stable answer that doesn’t exist, and you can’t reason about the choice in a vacuum anyway. You are better off going at it the way you would actually build it, from the model up, because each layer pulls you toward optimizing for something different. Get through all of them and the question of how to choose is much easier to answer.
The model matters less than it used to
The model layer comes apart into three questions that build on each other, first the models themselves, then inference, then how you route between them.
Start with the models. Frontier closed-source providers like OpenAI, Anthropic, and Google continue to dominate production, and the two capabilities that once set them apart, multimodal support and reasoning depth, have largely converged. Multimodal went from a Gemini lead in 2025 to a baseline capability in 2026, since nearly every serious model now takes images, PDFs, and other modalities natively. Reasoning depth has jumped just as far. Humanity’s Last Exam, a benchmark built to be brutally hard, sat around 9% for the best model not long ago and is answered at roughly 41% today. What that means in practice is that top-end capability has converged far enough that choosing a model on its benchmark scores is the wrong frame, because you are rarely picking the one model that can do the job. You are picking among several that can.
That pushes the decision down to inference, which is really a question about cost. For the same capability, inference has been getting about 10x cheaper per year. A GPT-4-equivalent answer cost roughly $20 per million tokens in 2022 and runs about $0.40 today, with the cheapest endpoints under $0.10, and Gartner expects inference to be around 90% cheaper again by 2030. There’s a catch worth holding onto, though. Cost per unit of intelligence keeps falling, but overall usage is climbing fast enough to cancel that out, so your bill doesn’t actually shrink even as each token gets cheaper.
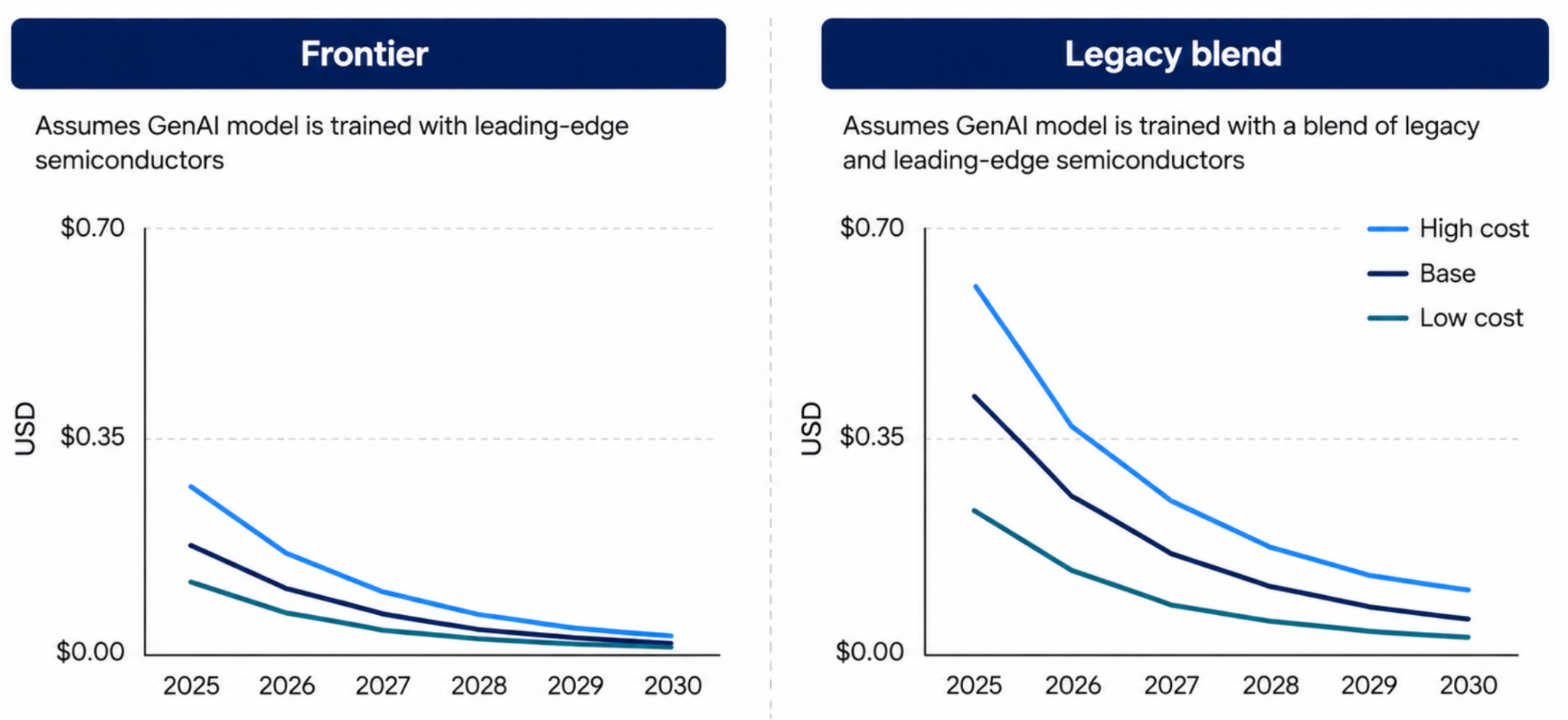
Cheap inference only turns into an advantage once you route it well. Mature 2026 systems rarely lean on a single model, running multi-model setups where an orchestrator routes each request by complexity, sending roughly 80% of requests to cheap specialist models and reserving the harder 20% for frontier ones, while the orchestration itself stays on the smartest model in the stack because deciding where to route is the hard part. Specialist models, often distilled from larger ones for reasoning or vision-language work, increasingly stand in for one model trying to do everything, and you can see the same sub-agent pattern inside frontier harnesses like Codex and Claude Code. The shift in 2026 is that frontier models have gotten good enough at predicting which tasks need less horsepower that the routing decision is moving from the human to the model. We are not all the way there, but it’s no longer something a builder has to hand-tune.
What decides this layer in practice is cost, the routing that manages it, and the freedom to change your mind later. Your stack should be able to swap a model without a rewrite.
Retrieval, memory, and the year of connectors
The agent gets its reach into the outside world from the middle of the stack, and capability has largely converged here too, so the decision has moved from raw capability to operational fit.
Retrieval is where that shift already happened. Vector databases have effectively commoditized in 2026, with most of them offering very similar capabilities so the choice now turns on operational fit rather than raw capability. What separates them is which integrations a provider already offers, what infrastructure you are already running, and how cleanly it fits your auth and access layer. Graph databases are taking more share than they had a year ago, on both the consumer and enterprise sides, and Andrej Karpathy’s “LLM Wiki” post popularized the idea of structuring a knowledge base as a graph so agents can find what they need without scraping through everything. Graphs still trail vector stores mainly because of ingestion. Dumping raw data in works for small use cases, but building good-quality graphs at scale is a project in its own right, which is why it’s worth reaching for one only when your retrieval genuinely needs relationships. Sitting alongside both, managed retrieval services like Glean blend RAG with traditional search and hand you the whole pipeline, trading knob-level control for infrastructure you don’t have to run. Hybrid search, which combines vector, keyword, and metadata signals, is now the production default, and naive RAG on semantic similarity alone is rarely shipped.
Memory looks like a separate layer, but in practice it overlaps heavily with retrieval. As a user interacts with the system, you capture what matters, things like their preferences, a project’s status, or an event they mention, and surface it again on demand, which is really external knowledge retrieval pointed at the user. What makes memory its own discipline is that the ingestion side is noisy. Users say a great deal, some of it contradictory, some of it overriding what they said earlier, and a naive store turns all that into garbage retrieval. Every serious memory player is opinionated about how to handle it, with Mem0, Cognee, and Zep running vector plus graphs, Letta using hybrid search, and SuperMemory built specifically for coding. The architectures differ, but underneath they are all RAG with a harder ingestion problem, so the choice comes down to how active the project is and what migrating the store would cost you later.
Tools are where 2026 earned the name “the year of connectors.” Rather than building separate integrations to email, calendar, browsers, and web search, you increasingly reach for an aggregator that wraps many of them behind a single auth layer. Composio exposes dozens of SaaS connectors that way, Browserbase handles browser automation, Firecrawl handles web extraction, and Zapier and Make bring their own large libraries. Picking among them is almost entirely a question of how they connect, meaning which protocols they speak, how their auth model fits your security posture, and how thick the wrapper is, which is another way of asking how hard it would be to leave.
The protocol debate is still open
Part 1 framed MCP and A2A as connective tissue, which is the optimistic read, and the honest one is that the industry is split. MCP has wide adoption among model providers and is the default for most major harnesses, but it hasn’t become the HTTP of agents yet. An active counter-camp argues that CLI tools and existing APIs are enough, and that another standard just means another spec to maintain, with OpenClaw the notable example of a harness that leans CLI-first.
From Google’s agentic commerce protocol to fintech-specific standard, new protocols keep getting proposed for specific verticals too. The trouble is that a protocol only works once the industry aligns on it, and 2026 has far too many options on the table for that alignment to have settled.
Protocol-based integrations are cheap to maintain, but only if the protocol survives, whereas custom integrations have always carried a long maintenance tail regardless of what happens to the standards around them. So lean on a protocol when your team and your customers are already aligned on one, and stay light when you are building into an environment where the question is still unsettled. Bet on the protocols you can afford to be wrong about.
The decision that matters most: the harness
Once you have a model, the components, and a way to wire them together, you reach the choice that shapes everything sitting above it. More than the vector database or the runtime, the harness you choose to live inside is the decision that defines the build.
A harness is the wrapper around the model that turns it into something you can actually work in. Codex, Claude Code, Cursor, and OpenClaw are the products people spend real working hours inside, and the quickest way to see why the choice is structural is to picture building one yourself.
Say you want a basic coding agent that can answer “explain how authentication works in this codebase and who changed it recently.” You wire up a model. It needs to see the directory, so you add a shell-execution tool, then a file-read tool when it has to open things, then ripgrep when it has to search the repo. You teach it Git. You sandbox it so it can’t run git rm -rf. You add compaction because the context window blows up after three turns, then approval gates for anything destructive. Every one of those tools needs its description tuned, and every one breaks in its own way as model versions change.
That’s the build-it-yourself path. The harness path is a single command, codex on the terminal, with all of that wiring already shipped, tested, and opinionated. The opinions won’t fit your use case perfectly, but for most generic needs they hand you a working starting point before you write a line of code.
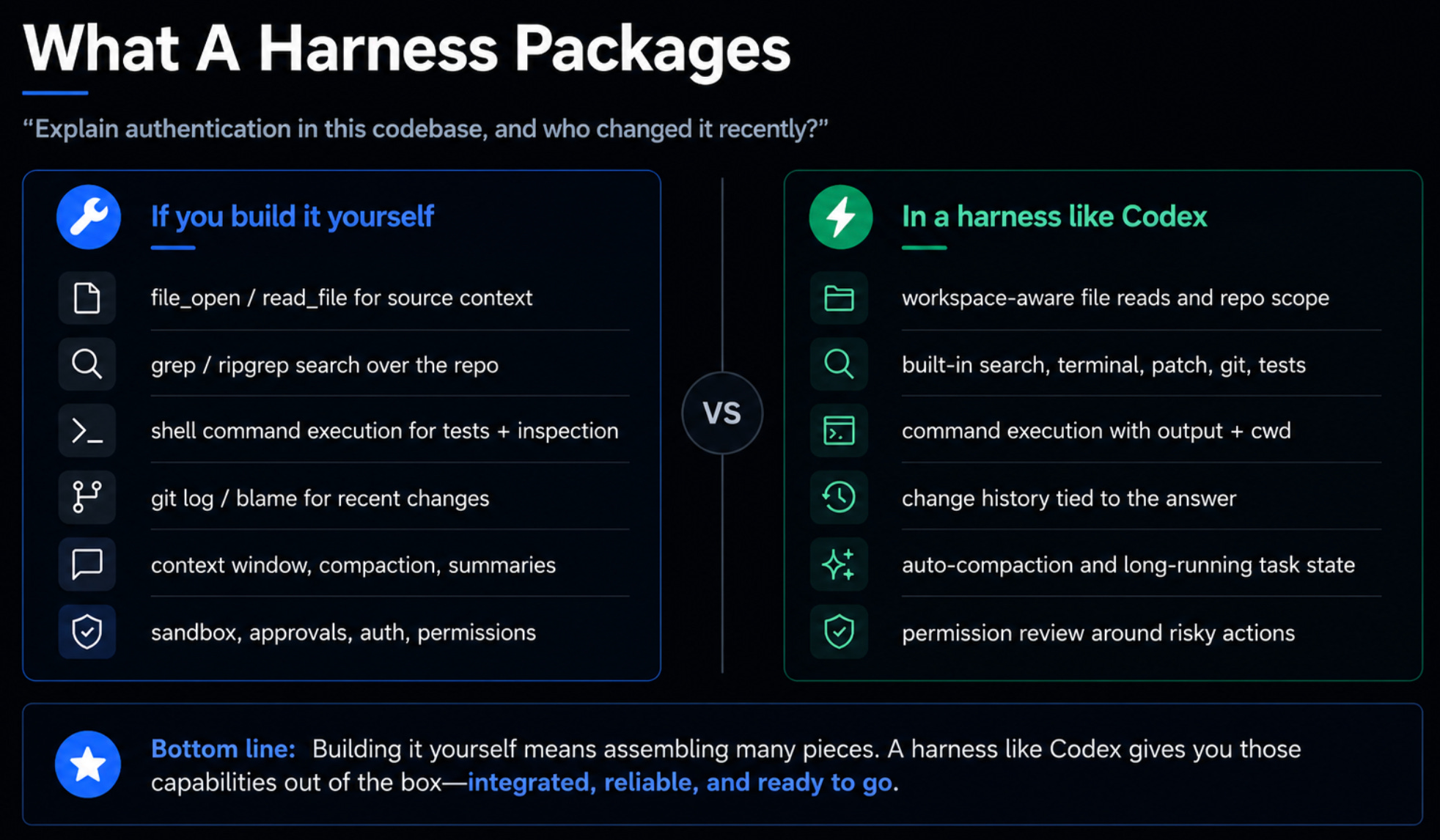
The bigger shift in 2026 is that harnesses are no longer just for coding. The same primitives, file reads, shell execution, search, sandbox permissions, compaction, turn out to be what you need for a PM drafting PRDs, a trip-planning agent reading PDFs, or a research agent summarizing reports, so Codex and its peers are becoming general-purpose knowledge-work harnesses rather than coding tools that happen to be useful elsewhere.
How far you can take one depends on its customization surface, which spans a spectrum. At the light end is an MCP config that wires a single external tool into the harness, and at the heavy end is a full plugin that bundles skills, scripts, and MCP servers into a distributed package, with skills, hooks, and AGENTS.md or CLAUDE.md files filling the space between.
Choosing among harnesses is the highest-stakes version of every judgment call in this piece. A handful of things separate a safe bet from a risky one:
How alive the project is. Most of the major harnesses are open-source, including Codex, OpenClaw, deepagents, and LangGraph, and Claude Code itself was leaked into the open. You can download Codex and ask it to explain its own architecture, where it stores plugins and how it manages context, which tells you more about its maturity than any feature page.
How much it connects to. For a harness, customization and integration are really the same surface, spanning everything from MCP servers and skills to hooks, plugins, and internal tools you wire in through configuration.
How well it documents itself. The docs need to read cleanly not just for your team but for the coding agents that will write automation against it, and plenty of fast-moving tools ship with documentation that’s already broken.
How much it locks you in. Plugin formats aren’t standardized, so a skill written for one harness won’t carry over to another.
How thick the opinionation runs. OpenClaw leans on CLI tools and stays light on MCP while others commit to it fully, so the right answer depends on the stack you already run.
Evals and Governance: proving it works, and keeping it safe
The two vertical rails, observability and evals on one side, governance and security on the other, are where the choosing changes character, because they are less tools you slot in next to the others than systems you build around everything else.
On evals, the 2026 shift is away from one-shot evaluation and toward a continuous improvement loop. LLM judges have become the default for grading agent outputs, mostly because at the edge of model capability it’s hard to specify in advance what good behavior even looks like. Code-based evals still have a place for specific, measurable metrics, but they can’t carry the load on their own. Tools like Arize Alyx now read your observability data as an agent and surface common failure patterns on their own, so you are no longer inspecting traces by hand to find what is breaking.
The real skill, though, lies less in picking the eval tool than in knowing which evals to build, and that knowledge comes from production data rather than a checklist. Multi-agent and multi-turn evaluation is still hard. You can grade against broad goals, like whether the agent solved the customer support ticket, but the specific things worth testing only become clear once you have watched the system fail with real users. An eval suite on its own won’t make a product good. What does is the loop of shipping, watching where it breaks in production, and feeding those particular failures back into the tests. The teams with the most reliable agents in the field are rarely the ones with the largest suites so much as the ones who have made that loop tight.
On governance, the shift has been from optional to non-negotiable. Real-time scanning is now standard, with very small models running in tens of milliseconds to check outputs without adding meaningful latency. Indirect prompt injection, where attacker-controlled content arrives through email, web pages, or documents the agent reads, has become common enough that vetting new data sources is routine practice. Defense in depth, sandbox policies, and approval gates have stopped being merely good practice and become a control-plane decision driven by regulation, with the EU AI Act and its equivalents elsewhere moving the whole area from goodwill into compliance.
With these two rails, the real question is less which vendor you pick than whether you have the capability at all, and what it costs you to be missing it. On every serious enterprise contract now, the procurement conversation opens with audit trail, human override, and policy enforcement, and the model question is often settled by the end of the first meeting.
Putting it together: A Financial Analyst Copilot
Suppose you are building a Copilot for a hedge fund. A user types in a stock ticker, and the agent pulls live price data, scans recent news, runs the firm’s standard thesis checks, drafts a memo, and posts it to Slack at 8 AM daily.

Trace it through the stack and you touch every layer. Slack is the part users see, but the agent loop itself runs elsewhere. Behind it, the harness decides which runtime carries that loop and which capabilities come pre-wired. The tools layer hands the agent a market-data API for the price and web search for the news, plus an internal retriever that reaches into the knowledge and retrieval layer for the firm’s own prior research. You would want it to sharpen over time too, learning which past memos landed and what each user likes to see, and that is the memory layer at work. The model layer pulls everything together into the final memo, with the heaviest reasoning on a frontier model while smaller ones handle routing and citation checks. Underneath it all run the two rails. Observability catches failed tool calls before they reach the user, and governance enforces approvals the moment the agent reaches for a sensitive source.
Almost any agent you build runs through these same layers and no single one of them decides whether it ships well. A model, a harness, tools, retrieval, memory, and two rails of monitoring and governance each come with their own crowd of competing players, and each carries its own trade-off between what’s cheapest today and what’s survivable in eighteen months. Which brings back the question: With this many choices, and every option racing toward parity, how do you actually pick?
Five dimensions that survive feature parity
There is rarely one winning player in any of these categories, and the leader today can be matched within weeks, so the honest answer to “which tool?” is not a tool at all but a way of deciding that outlasts the features themselves. Five dimensions do that work, three of them weighted heavily and two moderately, and the aim isn’t to score every option but to stop arguing about features when the real decision is about something else.

Adoption. Will this tool still be here in eighteen months? Look past the launch posts to the open-source activity, the health of the community, and how many people are actually talking about it on Reddit and X. A niche tool a friend built is fine for a side project, but for production the real question is whether the team has the runway and the community to keep shipping when the next model release breaks something.
Integration. This is where the weights shifted most in 2026. The agent is becoming the interface, and people will spend less time clicking through a tool’s UI than they will having an agent talk to it, so the question stops being whether it has a nice dashboard and becomes whether it speaks the protocols your agents already use. If it exposes no MCP server, no A2A surface, no native function-calling, you are back to writing custom integration code and carrying its maintenance queue.
Learnability. This has two sides to it. The first is how hard the tool is for your team to pick up, and the second, increasingly the one that matters, is how easily your coding agents can. A lot of AI tools today have documentation that is broken, out of date, or missing their newer features, and a coding agent that can’t read the docs can’t write reliable code against them, so the cost shows up in every change you push afterward.
Cost (with lock-in). This isn’t really about the sticker price but what it takes to leave. If a tool is so opinionated or so deeply embedded that switching means a rewrite, then a cheaper-looking option can be the expensive one. A tool that costs more today but lets you swap providers next quarter is often cheaper across the whole timeline than one that’s free until you try to get out.
Flexibility. It’s closely related to lock-in but not the same thing. What you are asking is which abstractions the tool sits on and how thick its wrapper is around them. A thick wrapper is quick to start with and slow to migrate away from, while a thin one takes longer to ship but reads cleanly when you swap the pieces underneath.
None of these five should feel new. They were the quiet logic behind every choice on the way up, from cost and swappability at the model to integration and fit at the vector store to all five at once at the harness. The dimensions just put a name to the pattern you were reaching for anyway.
The next twelve to eighteen months
The five dimensions hold steady but what moves is how much weight each one carries.

Runtimes and harnesses are consolidating. A year ago, picking a runtime was a major architecture decision, and now most are reaching feature parity, with the same thing happening to harnesses like Codex, Claude Code, and Cursor as they commoditize the way models did. The harness is also outgrowing coding, as companies reposition these tools into general knowledge-work harnesses that build your inbox, act as a chief of staff, schedule your meetings, or drive your task tracker, which means people whose day job isn’t shipping software will be working through them too. Adoption weight rises, because picking the harness that survives matters more than picking the one with the slickest feature today.
Protocols will win the wiring, eventually. Some standardization is coming, even if what the standard turns out to be is still an open question, because the direction of travel is one-way. As it firms up, lock-in cost falls on protocol-aligned tools and rises on the ones that route around it.
Memory and retrieval blur into one context layer. The cleanest production teams are already pulling the decision out of application code and into a unified layer that works out at request time whether to pull from an external store or from memory. Flexibility weight goes up, so the move is to pick storage that lets you change your mind without a migration.
Governance moves from optional to mandatory. As AI products go mainstream, audit trails, explainability, and human override stop being nice-to-haves and turn into requirements. Most products aren’t built for this yet, while the ones that win enterprise deals will be.
Eval infrastructure beats shipping first. Being early to an autonomous agent counts for far less than having the eval infrastructure to keep improving one. AI products need break-in time and real signals from how people actually use them before they get good, so the differentiator is the improvement flywheel, building the right evals, seeing whether the product works in production, and looping those user signals back into the evaluation system. Adoption weight on observability and eval tooling rises sharply.
Where to start
If you are at the start of a project, put the framework before the comparison chart. Score the alternatives across the five dimensions, weigh them against your own stack and timeline, and pick the tool whose score holds up when the next round of feature releases lands. Whatever wins on features today probably won’t be what wins next quarter, but whatever wins on adoption, integration, learnability, cost-with-lock-in, and flexibility usually still will.
If you are already mid-project, run the same audit over your most consequential picks and find the one that scored worst on lock-in, because that is where your next painful migration is going to come from. Plan it now, while the cost of it is still manageable.
This piece is a follow-up to The AI Agent Stack in 2026. It grew out of a lightning session that gave practitioners a clear mental map of the stack today and a way to reason about each piece when building an AI product. Similar sessions happen regularly in our Chai and AI community and All our Maven cohort members get access to them, check out our cohort here.