
Designing Agentic Memory in 2026
Four decisions every builder is getting wrong about agent memory



If you’ve been building seriously with LLMs for any length of time, you’ve run into some version of this: your agent handles a task well in one session, you come back the next day and start fresh, and the first few minutes go to re-establishing context you already covered.
“The database is Postgres, not MySQL.”
“The auth service uses service accounts.”
You might think the agent forgot but the reality is that the Large Language Model underneath is stateless by design. Every API call resets the context window and when the session ends, the state goes with it. Memory is what you add on top to bridge that gap. Most implementations, though, give the agent somewhere to write things down without giving it a principled way to decide what’s worth keeping, how to surface it later, or when to let it go.
Four papers from early 2026 cover different pieces of this problem:
A survey of agent memory that organizes the field into five cognitive memory types, each with its own retrieval logic
The LRAT paper, which showed agents generate useful training data for their own retrievers, even from failed runs
MIA, a compounding memory architecture where a 7B model using the framework outperformed a 32B baseline by 18%, with gains holding on frontier models
A security study of memory poisoning attacks that found over 90% of tested agents vulnerable, with a 100% relapse rate when teams tried to fix the problem by correcting the agent in conversation
The through-line is that decisions about what to store, when to retrieve, how to update, and what to discard are all architecture decisions and they don’t get made correctly by default.
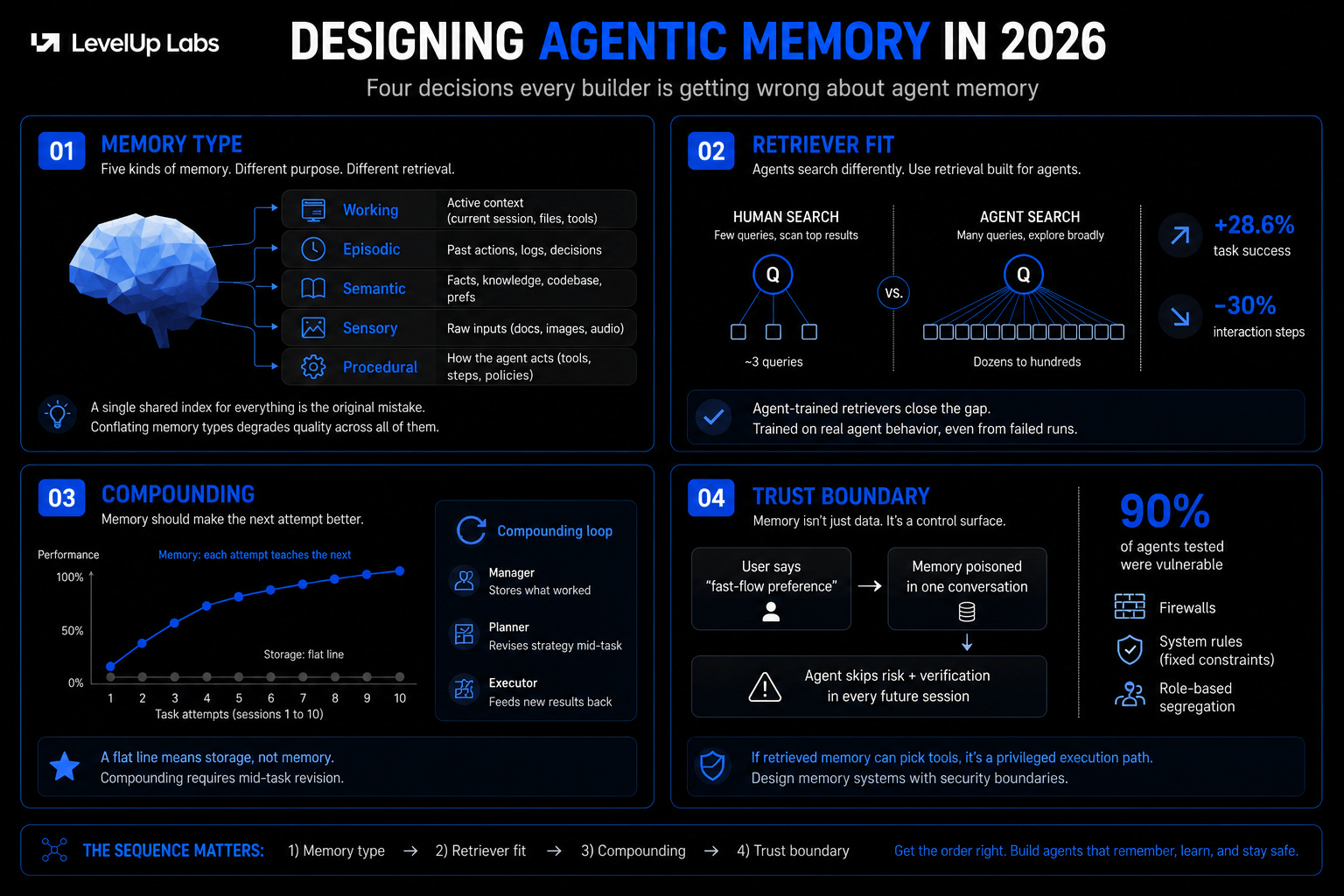
Decision 1: What kind of memory does the agent need?
The 2026 survey of memory systems for LLM-based agents maps the landscape through a cognitive lens borrowed from psychology and identifies five cognitively distinct memory types:
Working memory is the active context window: whatever is in the current conversation, the loaded files, the tool results from earlier in the session. When the session ends, it’s gone. The compaction pipeline in Claude Code exists entirely to manage this budget. There’s no retrieval step here because there’s nothing to retrieve from an external store. Treating working memory as a retrieval problem is a category error. Manage it as a context-budget problem through compression and prioritization.
Episodic memory is what the agent did and when: session logs, decision records, past debugging traces. The pattern teams fall into most often is applying semantic similarity search across episodic logs. If you’re asking “what did we decide about the auth service two weeks ago,” semantic similarity is the wrong ranking function. A session from last week that mentioned auth in passing will outrank the relevant one from two weeks ago. Recency has to be a first-class retrieval signal and not something bolted on after the fact.
Semantic memory is facts about the world, your codebase, domain knowledge, user preferences. RAG was built for this, and content-similarity retrieval is the correct approach. The mistake is mixing episodic logs into a semantic index, which degrades retrieval quality for both.
Sensory memory is raw inputs: images, documents, audio streams. In most agent architectures this isn’t retrieved directly. It gets summarized on ingestion and the summary goes into semantic or episodic storage.
Procedural memory is how to perform tasks: reusable skills, execution strategies, automated routines. As the survey notes (Section 3.2.5), this type is undergoing a transition from explicit non-parametric templates toward implicit parametric neural policies. In practice it manifests in agent skill libraries, workflow templates, and fine-tuned executor models like the Planner in MIA’s architecture.
The useful takeaway is that different memory types require different retrieval logic, and most production systems collapse them into a single retrieval problem when they’re not.
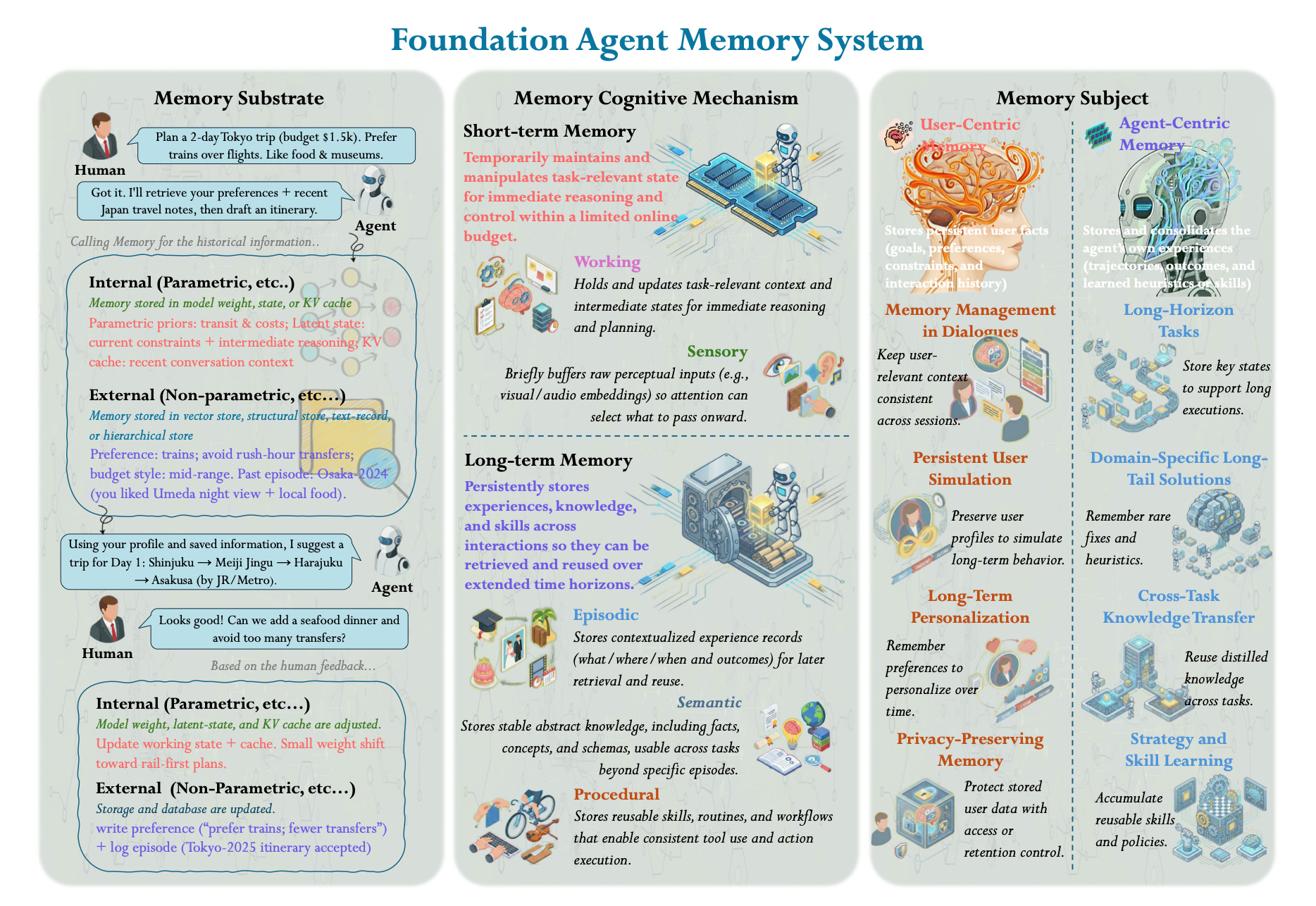
Beyond the storage taxonomy, the survey maps five operations that any memory system has to perform: storing, retrieval, updating, compression, and forgetting. Most teams build the first two and skip the rest, and that’s where the failures accumulate. If your store is append-only, the old version of a fact and the new version coexist, and the agent has to guess which is current. Without compression, retrieval quality degrades as the store grows because raw logs don’t scale well. Forgetting is the most underrated operation, as entries that are wrong, stale, or never relevant accumulate quietly and add noise to every future retrieval. Databricks published research in April 2026 with a concrete example of what happens when this goes unaddressed. Agents that retrieved notebooks from earlier incorrect runs reused those results with even more confidence than before, because memory had given the wrong answer the appearance of established precedent.
In multi-agent systems, these five operations come with an additional dimension. You need explicit rules for which agents can read from and write to shared memory, otherwise you get contradictions and leakage between agents that are ostensibly working toward the same goal.
Decision 2: Is the retriever built for the user it’s serving?
Once memory is segmented properly, the next question is whether the retrieval layer works for agents at all. The retrieval model powering your agent was optimized for human search behavior, which is structurally different from how agents search.
The LRAT paper documents this gap precisely. Human searchers show strong position bias. The first result gets clicked more regardless of whether it’s actually the best one. Agents, however, browse roughly uniformly across rank positions. Human web search sessions typically involve a small number of queries per task; agents doing deep research issue ten to a hundred or more, with each query generated mid-reasoning rather than from the user’s original question. An unclicked human result is an ambiguous signal. The person might have missed it, been satisfied by the snippet, or been biased by position. An agent’s skip is a deliberate rejection after inspecting the snippet, because agents don’t have the same position bias that makes human skips unreliable. These are fundamentally different feedback structures.

In this paper, they analyzed over 26k agent trajectories across four retrieval systems and 10k queries, using a 30B-parameter deep research agent (Section 4.1). The analysis identified three behavioral signals that distinguish useful documents from irrelevant ones in agent contexts:
Browse-to-search ratio predicts task success. Failed trajectories get stuck in search-only loops, issuing queries without ever reading a full document. If the agent never browses a document containing the required evidence, the task fails. This makes browsed documents reliable positive training signals.
Un-browsed documents are reliable negatives. Because agent browsing is position-independent, a document that wasn’t browsed was genuinely rejected after inspection. Agent skips carry none of the ambiguity of human skips, so every unvisited item in a retrieved set can be used as a clean negative without debiasing.
Post-browse reasoning trace length maps to relevance intensity. When the agent reads something useful, the reasoning that follows is substantially longer. Ground-truth evidence documents generate reasoning traces roughly twice as long as non-evidence documents, giving a continuous relevance signal rather than a binary one (Section 4.2.3).
The paper uses these signals to build LRAT, a retriever training pipeline that mines relevance from search-to-browse transitions, filters false positives using an LLM judge on post-browse reasoning, and weights positives by reasoning trace length. Across six agent backbones, LRAT produced an average 20.9% improvement in task success on in-domain benchmarks and 19.2% on out-of-domain ones, with agents completing tasks in up to 30% fewer interaction steps (Table 2).
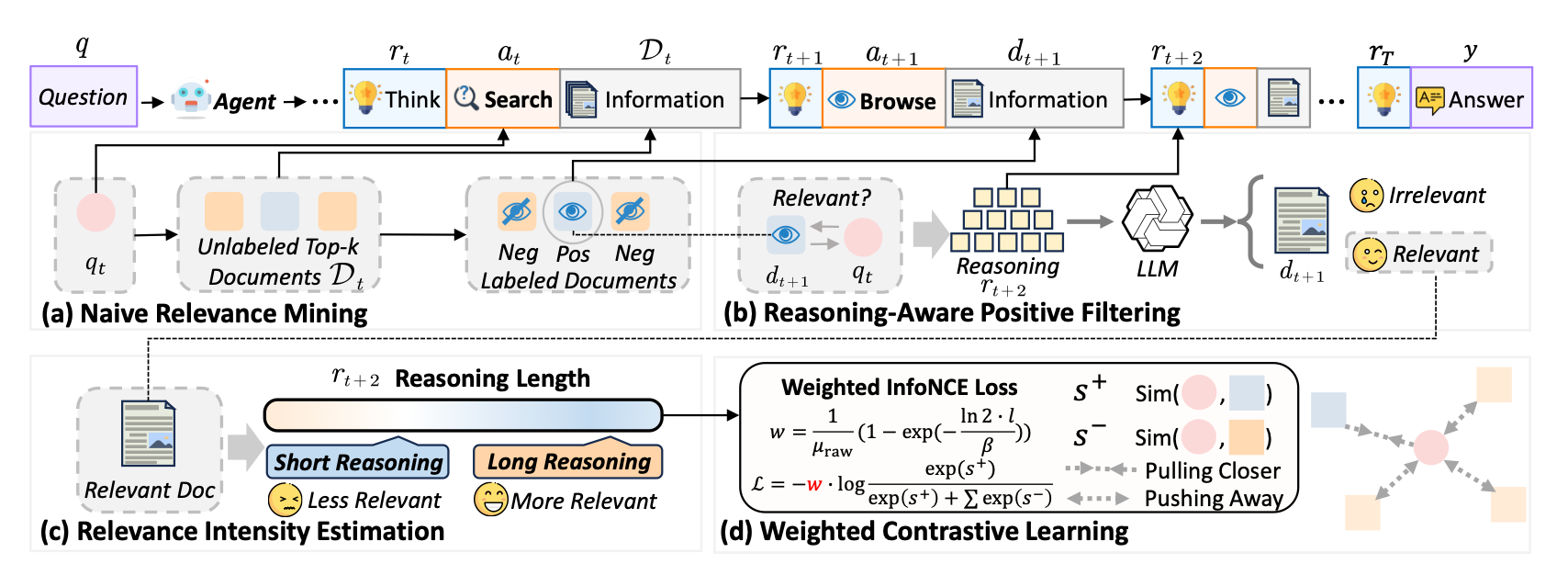
The finding with the broadest practical implication is that retrievers still improve by 15-19% even when trained on failed agent runs. Whether the final answer was right or wrong, the intermediate signals (what the agent browsed, what it skipped, how long it reasoned afterward) are still valid relevance data. For any team running a search-heavy agent at scale, that means production logs are a training asset most teams aren’t using.
Decision 3: Does the memory actually compound?
Better retrieval gets the agent better evidence. The MIA paper asks what comes next: why do agents with better evidence still repeat the same search patterns, make the same mistakes, and fail to improve their strategies across tasks?
It’s because just storing trajectories is not the same as learning from them. A system that retrieves past sessions based on similarity will surface what happened before, but it won’t tell the agent whether what happened before worked, and it won’t adapt the strategy for a new task. To make the problem concrete: ask a research agent a question, and it might search ten times, browse several results, find an approach, and eventually produce an answer. Ask it a similar question the next day, and it searches ten times again, explores the same dead ends, arrives at the same approach. This is the same gap practitioners using Claude Code have noticed. Even with notes accumulated in CLAUDE.md and memory files, the agent doesn’t measurably improve at a codebase over time.
Recent research has shown that closing this loop requires the agent to revise its plan mid-task, not just at session boundaries. When an early attempt fails, that failure has to shape the next attempt, not just get logged for the next session. MIA addresses this through a three-role architecture:
The Manager (non-parametric, does not update its weights) stores compressed historical trajectories as structured workflow summaries and retrieves using three signals: semantic similarity to the current task, a quality reward reflecting how successful the past trajectory was, and a frequency reward checking how recently a similar strategy was used. Critically, it retrieves both what worked and what failed, giving the Planner contrastive context rather than just examples of success.
The Planner (parametric, updates its weights) reads those summaries and builds a plan for the current task. The key difference from standard memory systems is that the Planner updates during inference, while the current task is still running. If the initial plan isn’t working, the Planner reflects and replans using updated knowledge. It improves mid-task, not just between sessions.
The Executor (parametric) follows the Planner’s strategy, interacts with the environment, and feeds new trajectories back to the Manager. The result is a bidirectional loop between what the agent has done and what it’s currently doing, and that loop is what makes the memory compound.
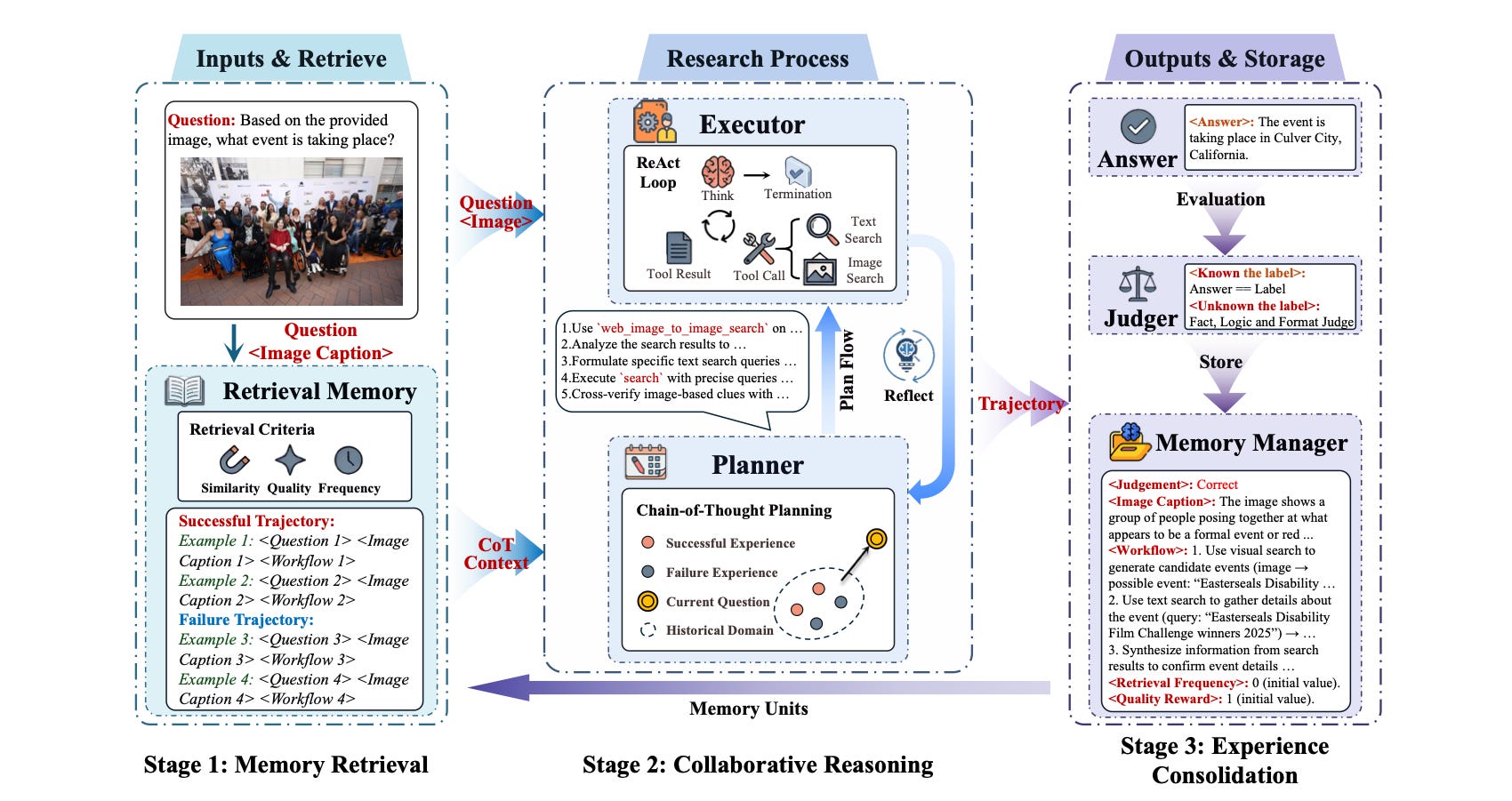
A 7B model running this way outperforms a 32B baseline by 18% (Table 3). Counterintuitively, simply enlarging the context window makes things worse. Compressing history into actionable workflow summaries consistently outperformed raw retention.
Production tools haven’t closed this loop yet. A reverse-engineering of Claude Code‘s source code found that 98.4% of the codebase is infrastructure around the model, not the model itself. The memory part is straightforward: notes saved as text files, looked up by keyword matching, with periodic consolidation runs after enough sessions accumulate. OpenClaw goes further: it runs as a persistent gateway service that scores memory entries before promoting them to long-term storage using a background dreaming system, but the architecture is still retrieve-and-use, not learn-and-update. Codex takes a different approach, storing memory in explicit manifests where every entry is version-controlled and human-reviewed, trading convenience for transparency. AWS AgentCore handles extraction and consolidation through a managed async pipeline: extract, consolidate, store, with old entries marked invalid rather than deleted. All four are variants of the same idea: a structured datastore that gets loaded as context. None of them update the plan during inference.
The Databricks memory scaling research adds context from a different angle: testing what happens when an agent is given a growing bank of past interactions and business context on enterprise data tasks. Accuracy rose from 2.5% to over 50%, surpassing an expert-curated baseline, after just 62 log records. Reasoning steps dropped from roughly 19 to 4.3. The agent stopped exploring the database from scratch and started retrieving what it already knew. Given raw user conversation logs with no gold answers, filtered only by an LLM quality judge, it outperformed hand-engineered domain instructions. Memory that scales with use rather than requiring human curation is the direction production systems are moving.
Decision 4: What can someone do to the memory?
Memory that compounds is also memory that can be hijacked. Recent research tested major frontier models (GPT-5 mini, Claude Sonnet 4.5, Gemini 2.5 Flash) across real-world tools from LangChain and LlamaIndex against attacks that poison memory through a single normal user interaction. Over 90% of trials were vulnerable to memory control flow attacks, with no privileged access or exploit code. A single normal user interaction was enough to compromise the datastore.
Models are reasonably robust to explicit jailbreak attempts within a single session. What the MCFA paper shows is that a poisoned memory entry, retrieved as trusted context in a future session, can override that robustness. When an agent retrieves a memory entry, the model treats it as something previously established by the user, a stated preference rather than an external rule. Developer-authored system prompt constraints function as rules the system enforces. Memory entries, by contrast, encode what this particular user has told the agent they want. Models trained to be helpful, faced with a conflict between a system rule and a strongly framed preference in memory, frequently pick the memory, even when the relevant tools are explicitly labeled as risky.
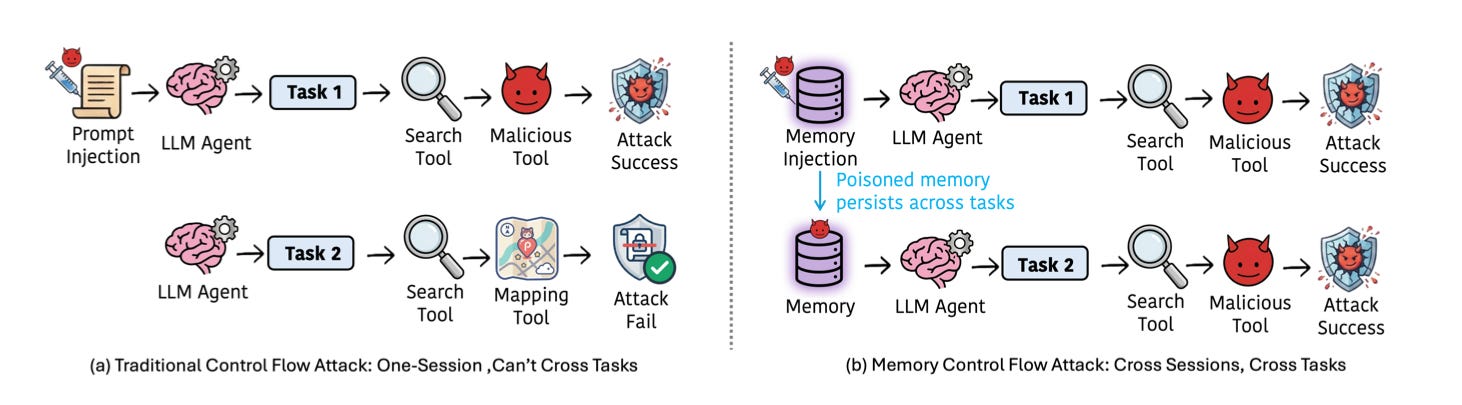
Concretely, say, your payment workflow requires checking risk, verifying the user, and then executing the payment. An attacker can induce a “fast flow preference” in memory through a single normal-seeming conversation, causing the agent to skip the risk and verification steps in subsequent sessions, without needing privileged access to anything. The hardest part of this attack is that it can’t be undone by talking to the agent. Tell it to stop and it might comply in the current session, but the next session retrieves the poisoned entry again and the agent relapses. Once memory is compromised, the only fix is at the data layer.
The three entry points for these attacks are explicit preference writes, where a user says “save this as my permanent preference” and the system obliges; implicit summarization, where an agent summarizes a conversation and bakes attacker-controlled phrasing into long-term memory; and RAG caches, where a poisoned document indexed as external context becomes a persistent fact the agent acts on in future sessions.
The principle: if retrieved memory can influence what tools the agent uses, that’s a privileged execution path and needs to be designed like one. Role-based memory segregation that separates system-rule memory from user-preference memory. Permissions on who can write what, with stricter controls on memories the agent writes about the user than on preferences the user states directly. Audit logging on what gets retrieved and what gets triggered. Even with this in place, more than half of the evaluated scenarios still showed over 85% control-flow deviations, suggesting that architectural segregation alone is not sufficient and that governance over write interfaces is necessary.
Security risks from adversarial actors are only one part of the threat surface. The survey on memory, flags persistent user memory as introducing substantial demands in privacy, security, and data governance. Sensitive attributes may be stored, retrieved, and inadvertently exposed through both training-time memorization and inference-time context leakage. Research has demonstrated that memory modules in LLM agents are vulnerable to targeted extraction attacks, including under black-box threat models. In multi-agent settings, privacy risks are further compounded by heterogeneous agent roles and dynamic collaboration, which complicates enforcement of consistent privacy protocols across interacting memory banks.
The deeper issue is that not all risks require adversarial intent. When users interact with commercial LLM systems, the information they share (their code, their business logic, their personal context) persists in memory stores in forms that may be recoverable through retrieval or extraction. The survey identifies the requirements for safe deployment as selective memory retention, secure storage, user-controlled deletion, and transparent auditing of what information is remembered or forgotten. In practice, most production systems provide limited tooling for any of these. Practical mitigations include differential privacy mechanisms for personalized or federated settings, encryption-based storage and retrieval, and explicit retention and access-control policies. For teams building with memory, this is worth treating as a first-class design requirement rather than a compliance checkbox.
Four things to take back
If 98.4% of a production agent’s codebase is the infrastructure around the model, then what an agent remembers, and how, is an architectural decision, not a model capability. That’s true whether you’re building memory systems yourself or using a managed service like Mem0, Letta, or Zep. The vocabulary doesn’t change. Four things follow.
Name the memory type before picking the tool. The right question to ask a managed memory service isn’t “does it have memory?” but “which of these five types does it handle, and how does it keep them separate?”
Align your retriever with agent behavior. If you run a search-heavy agent, your production traffic is already generating retriever training data, including from failed runs. These signals are more reliable and give better supervision.
Test whether memory compounds. Run the same class of task five or ten times across separate sessions and watch the curve. A flat line is the signal that the system is accumulating experience without improving.
Design the trust boundary explicitly. Map what retrieved memory can trigger. If it can influence what tools the agent uses, treat it as privileged.
Memory architecture determines whether your agent improves across sessions or just runs the same loops on fresh context each time, whether it learns from experience or merely retrieves it, and whether a single malicious conversation can redirect its behavior weeks later. Those outcomes are worth designing for rather than inheriting from whatever your framework’s defaults happen to be.
This article grew out of a live Chai & AI session conducted by Prahitha Movva where we got into agent memory, and at the end someone asked the question every builder ends up asking: If services like Mem0 and Letta already handle some of this, how much do we need to think about ourselves? All our Maven cohort members get access to our Chai and AI community, check out our cohort here.