
A Practitioner's Guide to Voice Agents in 2026
The voice agent stack: what works, what's coming, what to avoid




Most customers today no longer expect a chatbot to solve their problem. They expect to get past it. Three years of investment, three generations of models. Rule-based, then RAG, then GPT-4. Yet the share of conversations bots could close without handing off to a human barely moved. When Klarna’s CEO admitted in May 2025 that the company had “focused too much on efficiency and cost” and started rehiring support staff, most people thought that AI customer support isn’t ready. That’s not what Klarna proved. Klarna proved chat was the wrong channel for some of the work it was being asked to do. The question we should be asking is what AI support looks like on a channel that is fit for the job. The answer is voice.
Why the chat-era reading was wrong
Customer service is now the most-cited AI use case in the enterprise after content generation. McKinsey’s 2025 numbers put 88% of organizations using AI in at least one business function, with customer-facing work consistently at the top. Inside that category, voice and chat usually get treated as one bucket. They aren’t. They have different economics, different customer tolerance for latency, and different ceilings on what they can handle without escalating. Treating them as a single category is why the chat-era numbers looked worse than they were, and why voice is being underestimated right now.
The chat-era progression makes the point. Rule-based bots in 2022, RAG chatbots in 2023, LLM-powered support in 2024. Containment, the share of conversations the bot handled without escalating to a human, hit roughly 20%, 35%, 50% on anything non-trivial. The models got dramatically better. The wall did not move.
If chat were a model problem, better models should have moved the wall. They didn’t. Klarna was the public case. The pattern was everywhere.

Voice carries what chat throws away
Voice cleared the wall that chat couldn’t. Not because it handles simpler work, but because it carries signals that chat can’t. Customer service work runs on two dimensions: decision complexity (how much judgment is required) and emotional load (how much the customer’s frustration, distress, or trust is sitting on the conversation). Decision complexity is a model problem, and models are getting better at it on every channel. Emotional load is a channel problem, and chat is missing the equipment to detect it.
A pause in a phone call carries information. The customer is hesitating, gathering themselves, signaling that the next thing they say matters. The same pause in a chat window carries nothing the system can read. Tone, hesitation, the shape of “okay” when a customer is unsure versus satisfied, all of it is a real signal that text strips out before it reaches the agent. Voice doesn’t make the model better at handling that signal. It just makes the signal available. What the system does with it, including knowing when to hand off, is a separate design problem.
This is why chat hit a ceiling better models couldn’t fix. A smarter model can decide more complex things, but it can’t recover information the channel already discarded. The advantage compounds as models improve, because every gain on the decision side stacks on top of a channel that actually carries the customer’s signal in. Real-time voice models pushed speech-to-speech latency under 500ms, which solved the turn-taking and interruption problems that made voice feel mechanical for years. The unit economics flipped too: a voice minute costs more than a chat message, but it absorbs volume that was always too expensive to staff against in the first place. 80% of customer interactions still arrive by phone, especially the hard ones. The math finally works, but how do you start building with voice?
The voice stack, layer by layer
There are three layers to think about when building with voice: the model, the orchestration, and the infrastructure.
Layer 1: the model
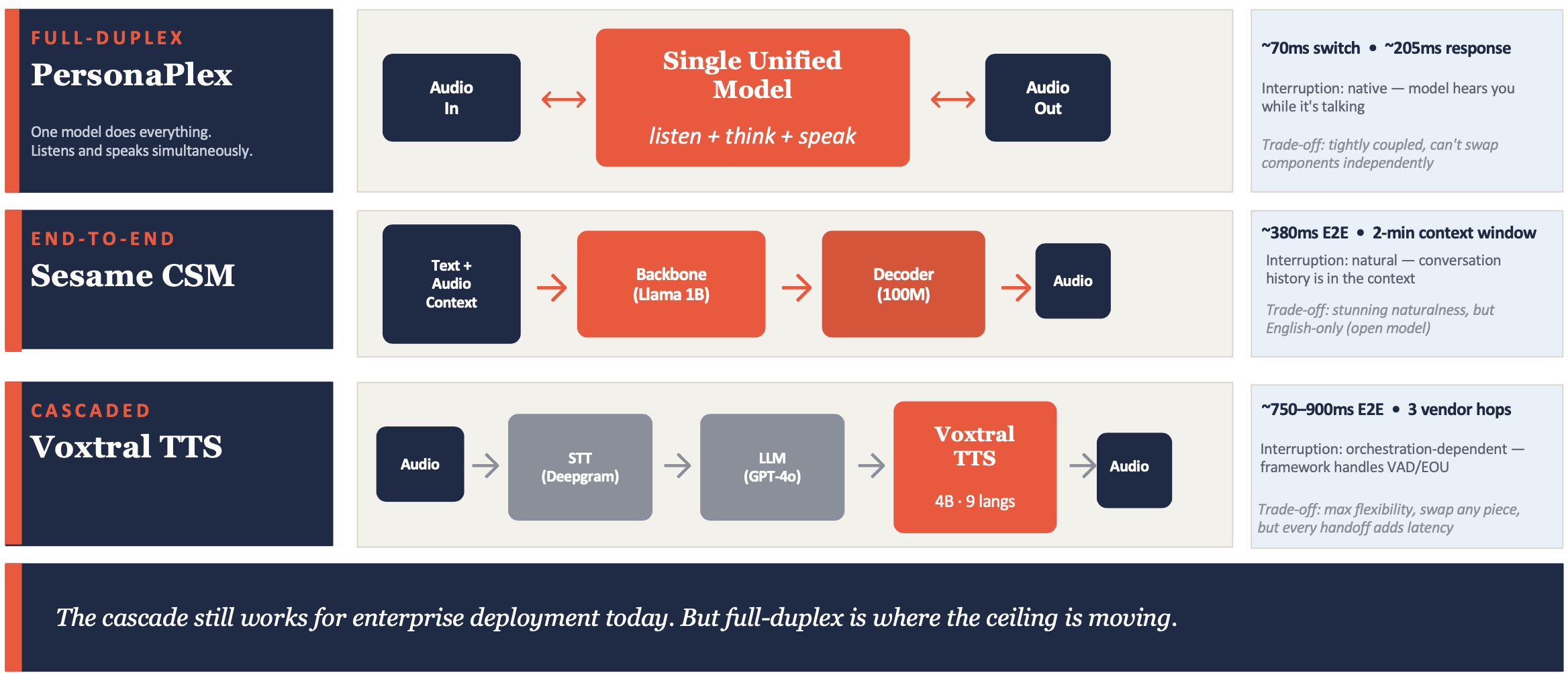
The model layer is the AI itself. There are three architectural patterns to choose from, and they aren’t really competing. They’re solving different problems, and they sit on a spectrum from loose coupling to tight integration.
Cascaded is three models in a relay race. Speech-to-text (STT) transcribes what the customer says into text. A large language model (LLM) reads the text and decides what to say back. Text-to-speech (TTS) converts the response back into audio. Each model is independent and can be swapped. End-to-end latency lands around 750-900ms. Modular, multilingual, SOC 2 compliance ready. This is what’s shipping in production today. Sierra, Decagon, and Parloa all run cascaded pipelines under the hood, and it’s what Hertz used to go from 10% to 70% call resolution in six weeks. The trade-off: every handoff between models adds latency, and each translation between audio and text loses information about how the customer actually said something.
End-to-end is two models trained together. A language backbone reads the conversation, and an audio decoder generates the response, but they share enough of their training that the speech output reflects the actual emotional shape of the conversation, not just the words. The result is the most human-feeling voice agents available right now. Sesame’s Maya is the public benchmark, listen to it for thirty seconds and you’ll have trouble telling it isn’t human. The trade-off: open-source weights are 1B parameters and English-only.
Full-duplex is one model that handles everything at once. Instead of listening, then thinking, then speaking, it does all three simultaneously, the way humans actually have conversations. Interruption handling is native, the model can hear you while it’s talking and adjust mid-sentence. NVIDIA’s PersonaPlex, released in January 2026, is the leading example: 70ms speaker-switch latency, native interruption handling, replaces the cascade entirely. It’s research-grade today, with no SOC 2 and no enterprise wrapper. But the gap between full-duplex and cascaded is large enough that when someone wraps a PersonaPlex-class model in an enterprise platform with compliance and Salesforce integration, the cascaded pipeline becomes legacy overnight.
The practical recommendation: if you’re shipping today, you’re shipping cascaded. Watch end-to-end for use cases where emotional presence is the differentiator, and watch full-duplex for the moment it crosses into production-grade.
Layer 2: the orchestration
Once you’ve picked your models, you need something to wire them together: handle the inbound call, route audio to each model, manage state, deal with interruptions. Two frameworks dominate. LiveKit Agents is convention-over-configuration: it makes default choices about audio routing, state management, and interruption handling so you can plug in your STT, LLM, and TTS and ship. Pipecat takes the opposite approach, you wire each component connection yourself. LiveKit is faster; Pipecat gives you more flexibility.
The performance gap between them is small enough that the choice rarely matters as much as people think it does. Pick one and move on.

Layer 3: the infrastructure
This is the layer most practitioners ignore, and it’s where the largest latency wins are sitting today. If your STT runs in Virginia, your LLM in California, and your TTS in Dublin, every round trip in the conversation crosses the public internet three times. That’s hundreds of milliseconds of latency you can’t get back at the model or framework layer.
Telnyx is an example of where this is going. They’re colocating GPU inference next to telephony PoPs (their points of presence in physical data centers), so STT, LLM, and TTS all run on the same private network as the phone infrastructure. The customer’s voice never leaves their data center until the response goes back out. Round trips under 200ms. Latency competition is moving here.
A rough rule for the whole stack: under 800ms total latency feels like a natural conversation. Over 1.5 seconds and the customer can tell they’re talking to a machine. The 700ms in between is what every layer of the stack is fighting for. But latency is only half the deployment problem. The other half is deciding what voice should and shouldn’t do.

The 30% you don’t automate
The teams getting voice right today aren’t the ones with the best models. They’re the ones who decided upfront which 30% of conversations they weren’t going to automate, and built the handoff so the customer doesn’t have to repeat themselves to a human.
The clean cut maps to the channel argument: voice handles the work where decision complexity is low and emotional load is manageable. Order status, account verification, appointment booking, payment dispute intake. The work where emotional load is high stays with humans, regardless of how good the models get. Distressed customers. Policy exceptions. Brand-critical interactions Klarna learned to call “VIP.” Voice can hit 70% containment on the first set today. It shouldn’t be trying to hit 70% on the second.
The harder problem is the broken middle, the seam where the voice agent hands off to a human. The customer re-explains the entire situation. The transcript is sitting in the queue but the human doesn’t read it. The tone shifts. This is where deployments lose customer satisfaction even when the front-end work is clean, and it’s where NICE, Genesys, Five9, and a wave of new startups are racing to plug the gap.

Where voice fits next
Once a team has the inbound deployment right, the next question is where else voice fits. Three candidates worth considering: appointment scheduling (confirmations, rescheduling, reminder calls), internal helpdesk (IT support for employees), and outbound SDR (sales reps making prospecting calls).
The strongest near-term bet is appointment scheduling. The conversations are tighter than support tickets: confirm or reschedule, hang up. The customer is already opted in — they made the appointment. The failure mode is recoverable — at worst, you get a no-show. And the volume is real: every business that runs on bookings has a queue of confirmation calls happening today.
Wherever you deploy first, voice doesn’t fix the AI failure modes chat exposed. Air Canada’s chatbot invented a bereavement policy that didn’t exist, and the company was held liable in court. DPD’s chatbot was jailbroken into swearing at a customer. Neither was a chat-channel failure. Both would have happened on voice with the same design choices. Voice doesn’t make hallucination or guardrail problems go away. It inherits them.
Before shipping, every team needs answers to four questions. What stops the model from inventing policy when the customer asks something it doesn’t know? What stops a hostile user from jailbreaking it into saying something the brand can’t recover from? Are the conversations bounded enough that 70% of them follow the same five branches? Is brand exposure low enough that a 5% failure rate is recoverable? If you can’t answer all four, you’re shipping the next Klarna reversal.
References
https://menlovc.com/perspective/2025-the-state-of-generative-ai-in-the-enterprise/
https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
https://www.forbes.com/sites/quickerbettertech/2025/05/18/business-tech-news-klarna-reverses-on-ai-says-customers-like-talking-to-people/
https://research.nvidia.com/labs/adlr/personaplex
https://sesame.com/research/crossing_the_uncanny_valley_of_voice
https://mistral.ai/news/voxtral-tts
This article grew out of a live Chai & AI session where practitioners debated where voice agents are actually working in production and where they aren’t. These sessions happen regularly and they get intense. If you want in, subscribe to The Nuanced Perspective to get notified.